Bueno, tuve que dejar un par de semanas de hacer post por que me acumule de trabajo y quería tocar este tema por que es algo que me parece muy útil para quien le toque ver temas referidos a la generación de excel con Spring boot o en general con java. Y para serles franco el código en este post no va a ser pequeño, por lo que hacer una demo que yo considero útil para varios posibles escenarios con los que se van a encontrar en algún trabajo y proyecto me tomo unas cuantas horas por lo que me demoro el desarrollo del post.
Espero que lo que revisemos y el código y video que deje les sea de provecho por si llegan a tener algún escenario como el que voy a plantear para iniciar con la explicación.
Escenario
Digamos que en su trabajo/freelo/proyecto personal, quieres realizar la generación de un excel. El modo más sencillo sería empezar a definir las columnas que va a tener y así ir dándole la forma al excel. Sin embargo, si queremos que este sea dinámico. Digamos que necesitamos un componente al cual le pasamos una estructura de datos y este nos genera un excel formateado y demás. Claro que el nivel de customización dependen de lo que se busque, pero un caso similiar tuve hace unos días en el trabajo y fue divertido por que me permitió aprender más sobre la librería en la cual me baso para esta demo, Apache POI, es de seguro ya conocida por mucho en el mundo de Java, teniendo en mente lo que acabo de plantear, veamos como esta distribuida nuestra demo.
Distribución del Proyecto

Como pueden ver en la imagen, tenemos las siguientes capas:
- Controller: Exponemos nuestro endpoint
- Model: Nos permitirá manejar de manera genérica la información de nuestro excel.
- Service: Ejecutamos la lógica para la generación del excel.
- Transversal: Son funciones que podremos usar a lo largo de la aplicación.
- Util: He creado varias funciones que nos permitán manejar mejor ciertos casos que se pueden presentar en la generación de un excel (formato de decimales, fechas, etc).
- Resources; Parte propia de spring, acá de ubica el yml de configuración. Sin embargo, también estoy poniendo el json del cual vamos a partir para generar el excel.
Revisemos ahora que tenemos en cada uno de los componentes:
Controller

Como pueden ver, estamos devolviendo a la petición GET un objeto del tipo Resource. Esto lo hacemos por que nuestro end-point retorna un array de bytes e indicamos en el header el formato del excel, en el key «Content-Disposition», además, de indicarlo en el content-type del response. En el siguiente post voy a explicar como se descargaría este excel desde una aplicación de angular sencilla.
Model


Sólo usaremos estas dos clases para manejar toda la información que queramos renderizar en nuestro excel, cuando revisemos las otras capas veremos como dinamicamente vamos generando el excel. Notese, que «Field» me permite mapear los campos que obtengo de base, por su nombre, descreipción y tipo de dato que como vemos es un enum. Estoy usando lombok para no llenarme de codigo de inicialización de las clases y demás.
Service

Este método es el que nos retorna el objeto Resource y por lo tanto es el se encarga de llamar a los otros métodos que nos permiten generar el excel. Antes de explicar que hace cada uno de estos métodos, comentar que «data» y «columns» básicamente están leyendo los json que tenemos en resources y los están parseando a un objeto con un método creado en utils que me permite hacer esto. Veamos que hacen los otros métodos:
generateFieldsReport:

Recorremos la lista de información de columnas para generar una lista de fields. Acá estamos usando el enum para determinar de que tipo de cada es cada columna de nuestro excel. Esto lo usaremos para el formato en un paso posterior.
buildCellTypes:

Obtenemos todos los tipos de datos que tendremos en nuestro excel.
buildDataLines:

En este método basicamente estamos obteniendo la información que va a llenar nuestro reporte de excel, en base al tipo de datos que ya obtuvimos estamos dándole el formato al cuerpo del excel en cada una de las columnas. Como se puede ver, estamos recibiendo la lista de maps que obtuvimos de la base de datos (nuestro json para nosotros).
createXlsxFileAsByteArray:

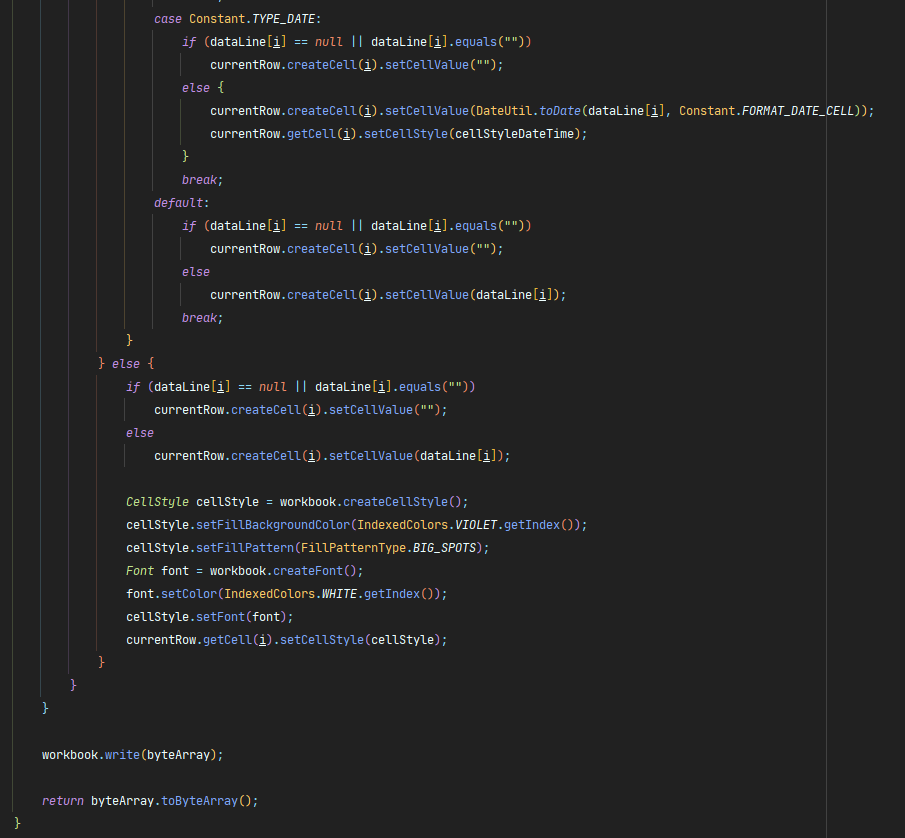
Finalmente, en esta capa, el método en el que ya trabajamos con Apache POI, acá generaremos el excel y lo convertiremos a un array de bytes. Empezamos creando un objeto del tipo «SXSSFWorkbook», dentro de este definimos un «Sheet» que es la hoja sobre la que trabajaremos, le ponemos el nombre que queramos. Las siguientes lineas me sirven para darle el formato de fecha a los campos que correspondan, lo defino a este nivel por que si se van creando conforme se recorren las filas de excel, se genera una excepción si nuestro excel tiene mas de 10 mil filas, dado que si definimos más de 10 mil objetos del tipo «CellStyle» en un mismo excel apache poi lanza una excepción. Empezamos a recorrer nuestro «dataLines» que si mal no recuerdan es donde se pusimos todo el contenido de nuestro excel y uno a uno vamos a hacer validaciones sobre cada fila, en la primera iteración no hacemos mayores validaciones por que es la cabecera solo seteamos esta cabecera y le damos cierto formato, a partir de aqui si nos vamos a valer de un switch por el tipo de datos para darle el formato de corresponda. Para finalizar, escribimos toda la información de nuestro workbook en nuestro objecto «ByteArrayOutputStream» y retornamos nuestro método con un «toByteArray()».
Ya en este punto, tenemos el bytes de array para devolver en el end-point. Las demás funciones utilitarias que se usan en el proyecto (leer el json, formatear decimales, fechas, etc) no las voy a explicar en el post por que sería extenderlo más y de por si ya a quedado muy amplio.
Saludos
Deja un comentario





























































