En el post pasado, revisamos que es una cola cuando hablamos de desarrollo, en que casos nos puede servir y que alternativas encontramos en el mercado para poder usarlas. Puntualmente, hicimos una demo de el uso de esta herramientas con SQS que es un servicio ofrecido por AWS. Sin embargo, buscando no extender el post y la demo demasiado conforme iba avanzando el post anterior, decidí que era mejor dividirlo en dos partes. En la primera, revisamos como crear desde AWS un usuario con los permisos necesarios para conectarse a una cola, en código con un proyecto hecho con spring boot conectarnos a esta y poder enviar mensajes.
En esta segunda parte, revisaremos como podemos suscribirnos a una cola, y estar a la escucha de nuevos mensajes.
Para poder conseguir esto, y no estar llenandonos de proyectos voy a usar el mismo proyecto en spring boot de la ves pasada, con la diferencia que creare algunos nuevos componentes, la idea basicamente es consumir una api desde un controlador, esta encola el mensaje y en un listener recibirlo e imprimirlo en consola.
Veamos que hemos añadido en nuestro proyecto inicial.
POM
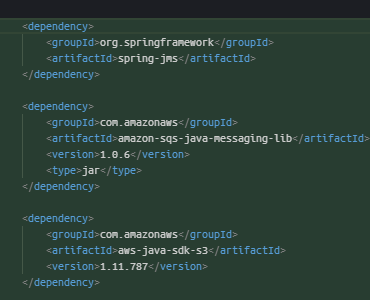
Nuevas dependencias en el POM
JmsConfiguration
Clase de configuración del JMS
SqsListener
Clases del SqsListener
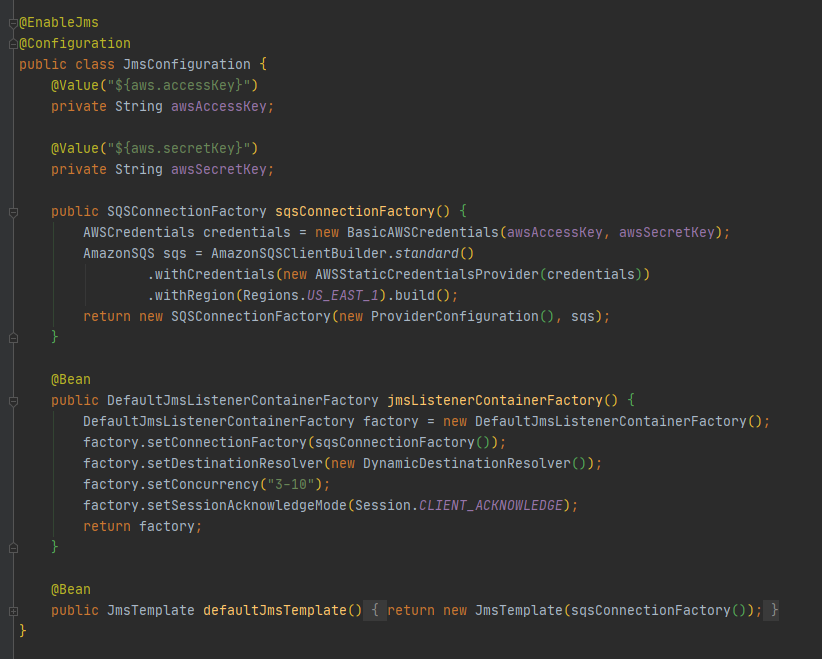
Con lo añadido en nuestro POM, tenemos acceso a clases de configuración que nos permitirán configurar un listener para las colas que ya tenemos definida en SQS. Si vemos a detalle la clase de configuración que hemos creado, tenemos lo siguiente:
Configuración en el JmsListener
En esta clase, como podemos ver, estamos creando un factory para las conexiones a AWS esto en el método «sqsConnectionFactory» y adicionalmente, configuramos nuestro listener factory para estar a la escucha de nuestra cola definida en AWS.
Como ven, tenemos que indicar que esta clase es de configuración con @Configuration, además de indicarse que habilite el JMS con @EnableJms. Sólo para aclarar por si hubiera alguna duda, JMS son las siglas de Java Message Service que es una clase definida en la librería JMS que nos permite realizar la creación y suscripción de mensajes a través de una cola.
Y finalmente, tenemos que crear nuestro listener, esto lo hacemos del siguiente modo:
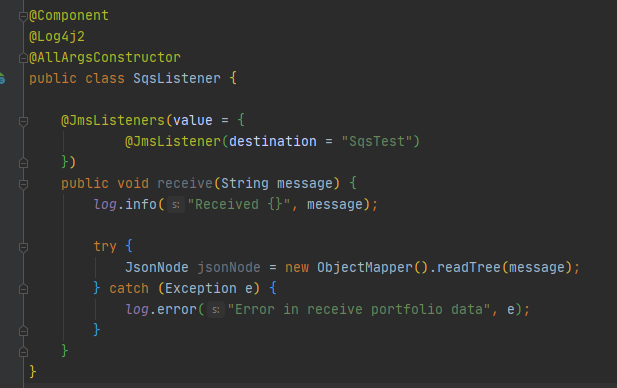
SqsListener
Creamos una clase y dentro creamos un método void con las siguientes anotaciones «@JmsListeners» que tiene dentro un «@JmsListener». Es necesario dentro de esta última anotación indicarle cual es el nombre de la cola que vamos a estar a la escucha en nuestro listener.
Hagamos una prueba de todo junto.
Primero realizamos el consumo de nuestro controlador con una mensaje cualquiera.
Consumiendo el API
Recibimos el mensaje en nuestro controlador.
Recibiendo el mensaje en el controlador
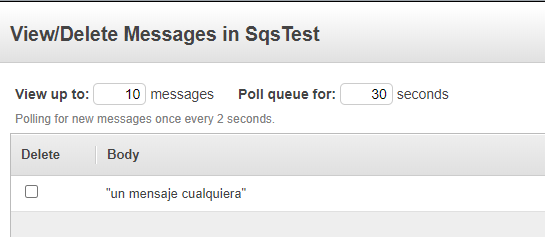
El mensaje es enviado a nuestra cola previamente configurada en SQS.
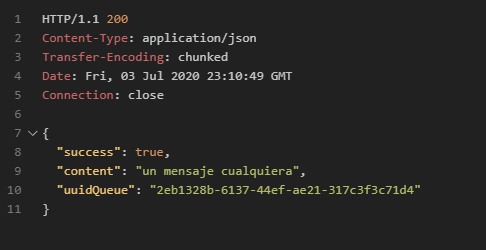
Se genera el mensaje correctamente
Mensaje encolado en SQS.
Mensaje en SQS
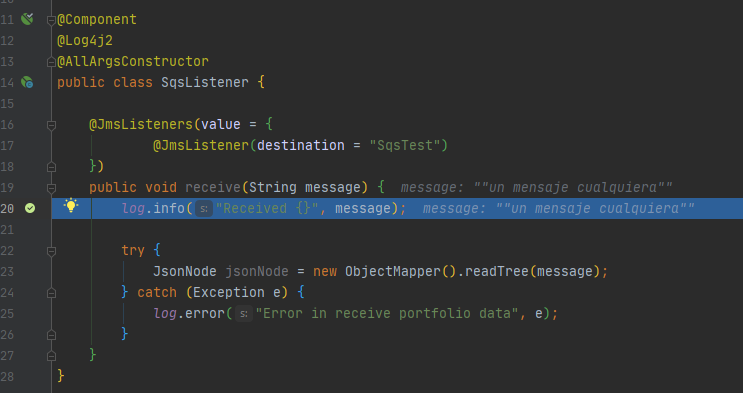
Ahora, segundos despues de que se encoló el mensaje, debería llegar a nuestro listener que esta escuchando la misma cola «SqsTest».
Recibimos el mensajeLog del mensaje
Con esta prueba concluye este post. El código lo subire como una actualización al proyecto anterior. Espero que les sirva, como ven es sencillos tener un manejo de colas funcional con sólo un poco de código. Dejo el link del repo y el video.
Hola, hace ya algún tiempo desde el último post, la verdad es que la cuarentena nos a permitido a todos tener más tiempo con la familia, pero también a los que nos dedicamos al desarrollo de software nos hemos cargado de trabajo. En mi caso, especialmente por que mi familia tiene un colegio y he tenido que asumir la migración a la enseñanza virtual.
Bueno, vamos al tema que nos reclama este post, en el proyecto en el que me encuentro trabajando he tenido la oportunidad de meterme a bucear por distintos servicios de AWS que estamos usando en la arquitectura. Este proceso a sido desafiante y de mucho aprendizaje, y quiero plasmar en una serie de posts mi exploración a los servicios de AWS. Empezando por el servicio de SQS que es basicamente un encolador de mensajes, sólo que es la alternativa que nos ofrece AWS. Deben ya de conocer algún servicio similar a estos, que yo recuerde ahora uno con el que hice una pruebas era RabbitMQ, que era un software open source que tenías que instalar en tu pc o en el servidor en el que lo quisieras usar y te permitia generar las colas y suscribirte a ellas, y realizaba el manejo de los mensajes que ibas encolando.
Me parece importante detallar un poco bajo que condiciones es necesario usar este servicio. Usualmente, cuando tenemos varios microservicios (puede entendeser como varias APIs), entrar a detallar de las caraterísticas que la hacen un microservicio va a extender mucho el post así que dejemoslo ahí. Pero cuando queremos que estos se comuniquen, podemos directamente hacer una solicitud http entre ellas y de ese modo la solicitud sería instantanea. Sin embargo, que sucede si son miles de peticiones, si alguna se cae o si se satura el microservicio que estamos consumiendo, como tener un control en la llegada de estas peticiones.
Teniendo en cuenta esto, es que entran a tallar soluciones de encolación de mensajes. Dado que nos permiten enviar mensajes (peticiones) a una cola que tengamos definido (inclusive definirla en tiempo de ejecución) y luego el suscriptor a esa cola va a ir desencolando los mensajes y procesandolos uno a uno. Del modo más básico esto es lo que se consigue usando este tipo de herramientas y amazon nos provee este servicio con SQS.
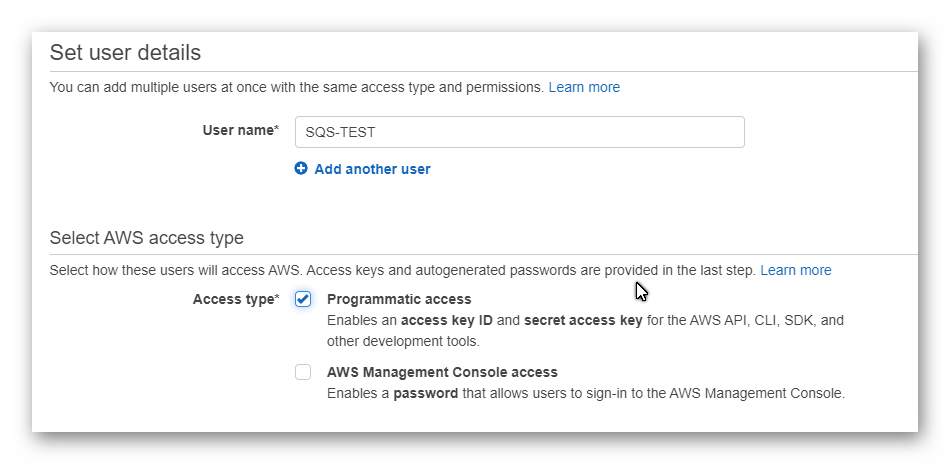
Entonces, ya teniendo claro para que podemos usarlo, veamos como se implementó. Primero debemos de tener una cuenta de AWS creada, en este punto quiero aclarar que si bien todos los recursos que voy a crear puede ser hechos desde un json y luego deployados con cloudformation en AWS o desde el AWSCLI, yo voy a usar la web de amazon por que me parece que es la forma más simple de hacerlo y a propositos de esta demo me sirve más. Con la cuenta que debemos tener, es necesario ir a IAM y crear un usuario que tenga asignado el siguiente rol:
Creacion de usuarioIndicar permisos
Luego no olviden copiar el access-key y secret-key que nos va a brindar IAM. Ahora veamos el proyecto en spring que hemos creado.
Usaremos las siguiente dependencias, en el POM:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-aws-messaging</artifactId><version>2.0.1.RELEASE</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.12</version></dependency>Lenguaje del código:HTML, XML(xml)
Estructura del proyecto
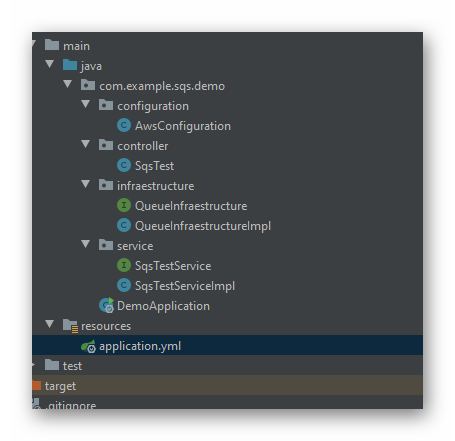
He dividido de módo básico en capas el proyecto, quedando del siguiente modo:
Controller: Y sabemos para que es esta capa.
Service: Para ejecutar la lógica que necesitemos.
Configuration: Para realizar la configuracion inicial de aws.
Infraestructure: Acá ejectuamos las acciones en las librerias externas que usemos.
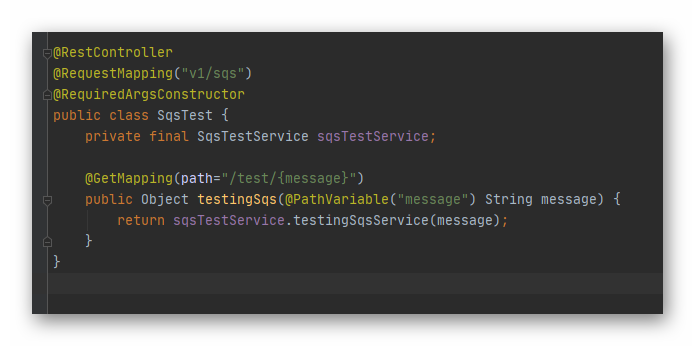
Nuestro controlador, es un endpoint que recibe una path variable que sera lo que encolaremos.
Controller
En nuestro service, llamamos a nuestra capa infraestructure para pasarle nuestro mensaje y que realice en encolado, estamos devolviendo un objeto anonimo, que indica si se registro correctamente, el mensaje que se a encolado y el uuid que nos retorna aws cuando generamos el encolado.Veamos que hace el método marcado.
Service
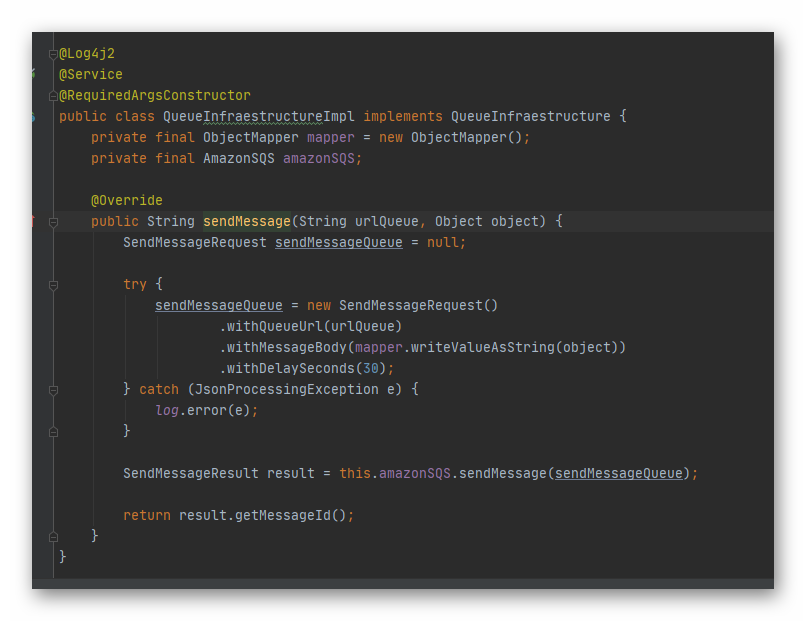
Como pueden ver, preparamos el objeto que vamos a encolar, estamos usando un ObjectMapper para convertir el objeto que recibimos (en nuestro caso un string) a un formato json y esto encolarlo. En este punto, también indicamos cual es la URL a la cual se dedbe encolar, la cual obtuvimos en el service por injección de dependencia directamente desde nuestro archivo yml.
Infraestructure
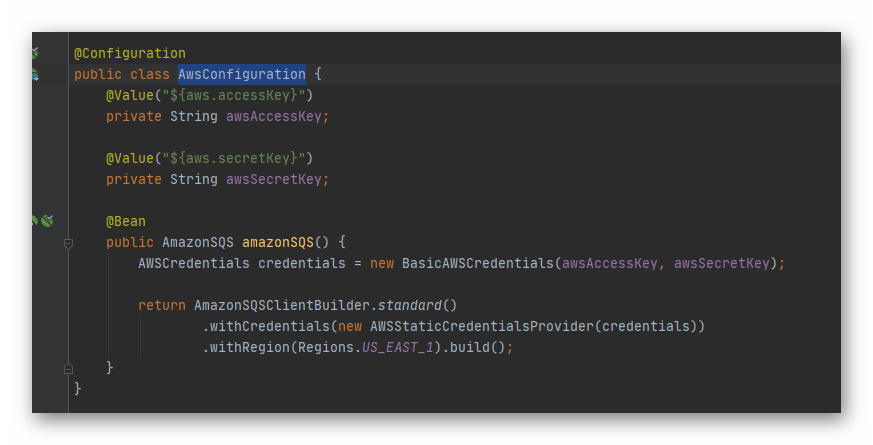
Revisemos que configuración tenemos en nuestro «AwsConfiguration». Como pueden ver, por injección de dependencia obtenemos el accesskey y secretkey que hemos generado al iniciar todo y los seteamos en el «BasicAWSCredentials» que luego usamos para generar un objeto del tipo «AmazonSQS», que es el que nos permite encolar la información entre otras cosas.
AwsConfiguration
Mientras realizaba el desarrollo del post, me di cuenta que hacer el listener de esta cola en este post iba a hacer que sea demasiado extenso. Por lo que termine decidiendo que en el próximo entrare a cubrir este detalle. Espero que les sriva y si tienen alguna duda pueden contactarme por alguno de los medios que he dejado, ver el video o revisar la documentacion oficial de AWS que es muy buena y completa.
Hola, aún en cuarentena aprovecho para hacer un breve post sobre integración y deploy continuo. Como deben de haber notado, luego de todo el proceso de desarrollo que hemos cubierto en algunos post que he realizado antes y con distintas tecnologías, siempre terminamos la demo realizando una prueba de nuestra aplicación mientras esta en debugging. Sin embargo, en un escenario real sabemos que esto es inviable. Dado, que necesitamos que nuestra aplicación este desplegada en un ambiente productivo. Cuando uno inicia en el mundo del desarrollo, probablemente no es quien se encargue de hacer los pases a producción y es muy probable dependiendo en que empresas estés trabajando, que este pase sea un simple «copiar y pegar» de una carpeta a otra manualmente, o que tengan una solución automatizada para llevar esto a cabo.
Esta última es la que me encargaré de desarrollar en este post. Yo he podido vivir ambos tipos de despliegue, siendo el más gratificante los últimos por que puedes ver que si bien es cierto la configuración inicial requiere más trabajo, además de tener ciertos conceptos claros, te permite automatizar los despliegues futuros eliminando el factor humado.
Primero, tengamos claro que para conseguir un proceso de CI y CD tenemos distintos stacks de tecnologías, entre las más grandes podríamos mencionar a azure, aws, jenkins, etc. Y también podemos encontrar variantes entre las que son libres y las que te ofrecen una serie de servicios adicionales como escalamiento y demás. Para la demo que voy a realizar, he decidido optar por hacerla usando VSTS (Visual Studio Team Services) que es basicamente un servicio ofrecido por microsoft que nos permite mapear todos los procesos del desarrollo de software, desde la gestión que se debe realizar hasta el despliegue. La estoy usando por sobre otras, por que es gratuita con sus limitaciones, y es accesible sólo con tener una cuenta de microsoft.
Mi idea, es generar un proyecto MVC con net core de 0, mapearlo a un repositorio como puede ser github, luego vincular nuestro repositorio a nuestro pipeline en VSTS y desde ahí configurar los archivos YAML indicandole los pasos que debe seguir. Para el hosting de nuestra aplicación demo, no estoy usando ninguna de las alternativas que ofrece Azure, por que quise hacerlo en un hosting propio en el que tengo una cuenta así que por medio de una tarea FTP, paso los archivos.
Primero, debo comentar que cuando queremos generar un proyecto con netcore desde la consola y no queremos usar la última versión que tengamos instalada, en cambio queremos indicarle una es necesario crear en la carpeta una archivo «global.json» indicandole esto al cli. Empecemos poniendo los comando que debemos usar para crear nuestra aplicación demo:
$ mkdir demo-mvc-ci-cd # creamos la carpeta donde alojaremos nuestra aplicación
$ cd demo-mvc-ci-cd # ingresamos a la carpeta
$ echo > global.jsonLenguaje del código:PHP(php)
En el archivo que hemos creado en necesario ingresar un json con la siguiente estructura.
{
"sdk": {
"version": "2.2.401"
}
}Lenguaje del código:JSON / JSON con comentarios(json)
En el cual, como ven indicamos la versión del sdk queremos que se use. Una ves creado esto, podemos crear nuestra aplicación netcore.
$ dotnet new mvc # nuestra aplicación tendrá el mismo nombre de la carpeta
$ dotnet restoreLenguaje del código:PHP(php)
Hasta aquí, tenemos nuestra aplicación en netcore creada, ahora inicializemos nuestra repositorio con git, previamente en mi caso he creado un repositorio en github para almacenar ahí nuestra aplicación.
Ya con nuestro código en github, es momento de ir a VSTS, les comento que con sólo tener una cuenta en microsoft (outlook, live, etc) ya tienes acceso a este servicio. Al inciar debemos crear un proyecto si es que aún no lo tenemos, en mi caso es un proyecto que he llamado demo.
Proyectos VSTS
En nuestro proyecto demo, podemos hacerle seguimiento a todos los procesos de desarrollo de software de nuestra aplicación. Sin embargo, nosotros vamos a centrarnos sólo en la integración y el deploy continuo. Vamos a la siguiente opción.
Opción del menú
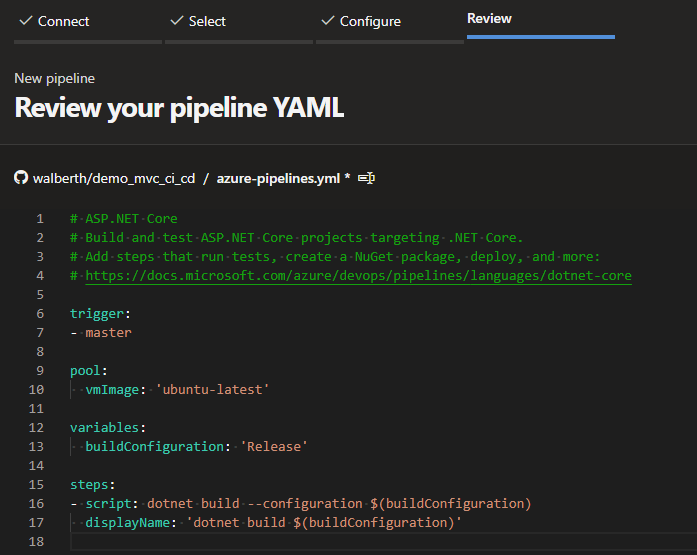
Creamos un nuevo pipeline, y nos preguntará donde está nuestro código, en mi caso mi repositorio está en github así que le indicaré que lo obtenga de ahí señalándole el nombre del repositorio. Luego de esto nos pide que elijamos el tipo de tecnología que deseamos compilar, en nuestro caso elegimos net core y nos carga la siguiente plantilla:
Plantilla YAML
Acá debemos realizar varios cambios, veamos uno a los lo que debemos poner.
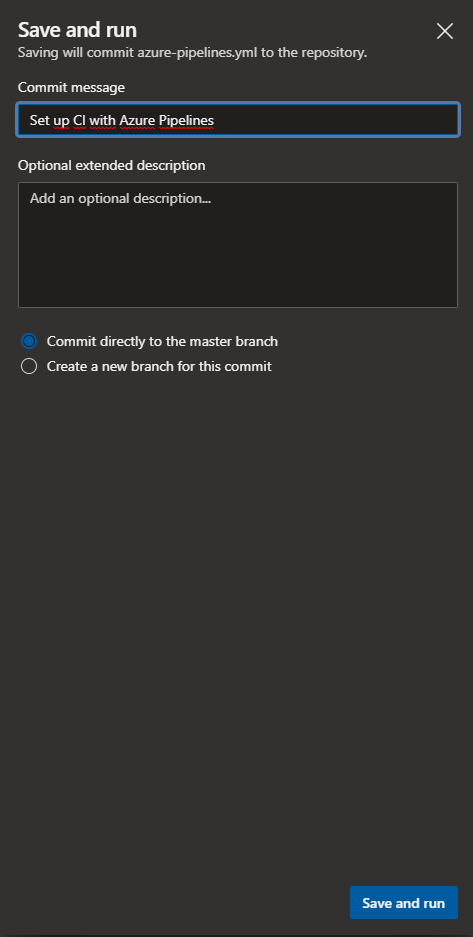
En steps, debemos añadir tareas de netcore, la primera es para restaurar los nuggets que necesitemos, la segunda es realizar un build de nuestro código indicando que es en release, la tercera es realizar la publicación de nuestro compilado con netcore, dejándolo en «$(Build.ArtifactStagingDirectory)» que es una variable de entorno de VSTS y finalmente, la última tarea es para copiar ese compilado a la carpeta final en la que la tendremos lista para poder obtenerla desde nuestra tarea de despliegue continuo. Grabamos todos los cambios realizados.
Grabamos cambios
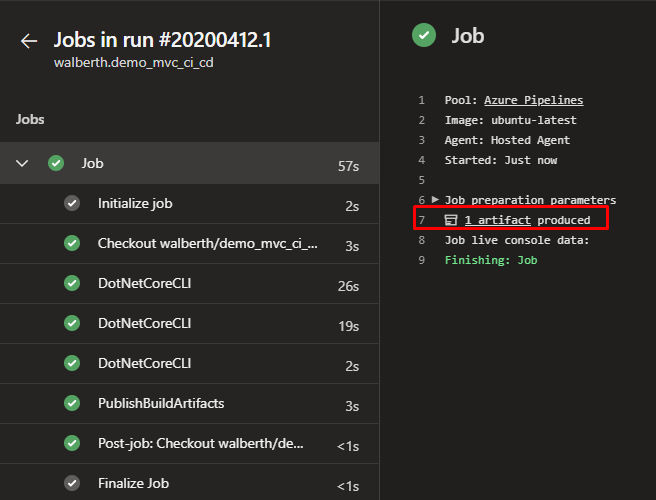
Cuando empieza a correr, tenemos la siguiente vista.
Actividad en la cola
Realiza las actividades
Como podemos ver en la última imagen, el proceso se a llevado a cabo de-acuerdo a lo que le hemos indicado, ha realizado todos los pasos y al final a desplegado el artefacto donde le indicamos que lo haga. Ahora vamos a ver como realizar el despliegue continuo.
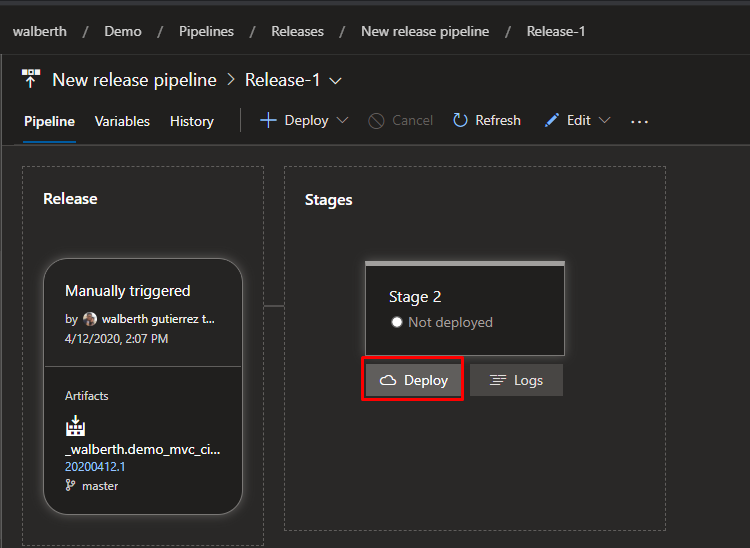
Para esto, vamos a la opción de releases y creamos uno nuevo.
Creando un nuevo release
Seleccionamos el artefacto que vamos a usar y se lo indicamos al release.
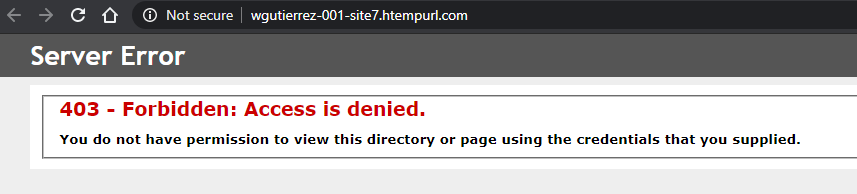
Luego de añadirlo, es necesario que le indiquemos los pasos que vamos a usar acá tenemos un sin fin de opciones y de las más variadas, en mi caso simplemente realizaré una tarea FTP para que se conecte al site donde debe dejar el compilado. Si intentamos entrar a este site ahora tendremos la siguiente respuesta.
Respuesta del site antes de publicar
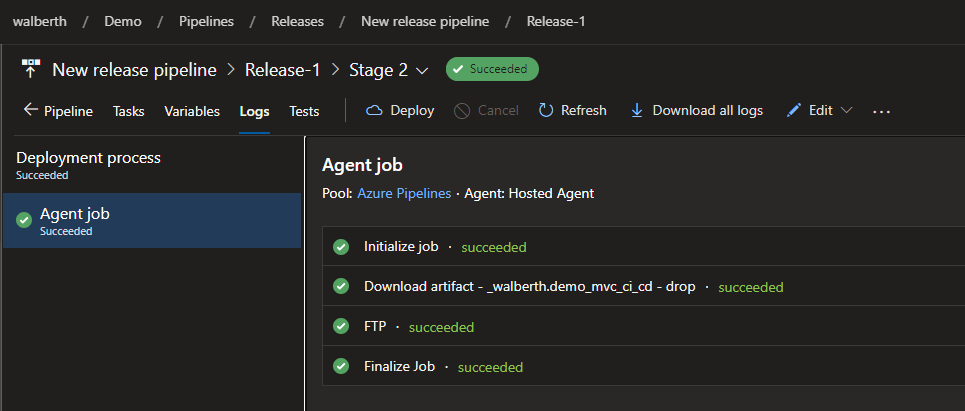
Agregamos nuestra tarea FTP.
Tarea FTPInformación FTPGrabamos nuestro releaseRealizamos el deployRealiza el proceso de despliegue
Si en este punto, validamos nuestra web, debería de tener nuestra aplicación ya desplegada.
Aplicación
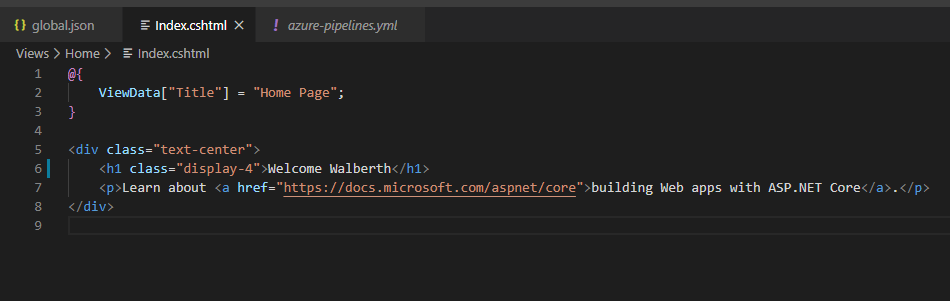
Finalmente, hagamos un cambio en la aplicación, luego realizar un commit y push a master y luego de unos minutos deberíamos de tener nuestra despliegue realizado.
Cambio en la app
Luego de unos minutos que todo nuestro proceso automatizado se lleva a cabo, vemos nuestra web nuevamente y el cambio esta reflejado.
Cambio reflejado
Bueno, con esto concluyo el post que al final no salio tan chico. Espero que les sea de utilidad, igual pueden dejarme algún comentario o comunicarse conmigo por alguna de las redes sociales. No dejo link de github en este caso por que esta demo no iba enfocada en código.
Hola, aprovechando un poco el paro que estamos teniendo en Perú por un aislamiento que a decretado el estado me di un tiempo entre el trabajo remoto y otras responsabilidades para hacer una pequeña demo sobre el uso de autenticación en Angular, específicamente como podemos valernos de interceptores y guards para poder trabajar con json web tokens (JWT).
Hago la demo de este punto en especifico por que recibi un par de preguntas la semana pasada sobre este tema y me di cuenta que en su momento para mi también entender ciertos conceptos y como se usaban me costo un poco y decidí hacer una demo y un post sobre esto.
Para explicar un poco como he decidido dividir la demo, el proyecto en angular se ha desarrollado desde 0, valiéndome de angular cli para generar la estructura básica de angular y sobre esta cree dos componentes una publico y otro protegido además de otras carpetas para los intercetores, guard y servicios. Del lado del backend, para generar nuestros JWT me estoy valiendo de una aplicación que ya tengo realizada y sólo he modificado el endpoint para generar el token y retornarlo. Veamos con más detalle nuestra aplicación en angular.
Estructura del proyecto en angular
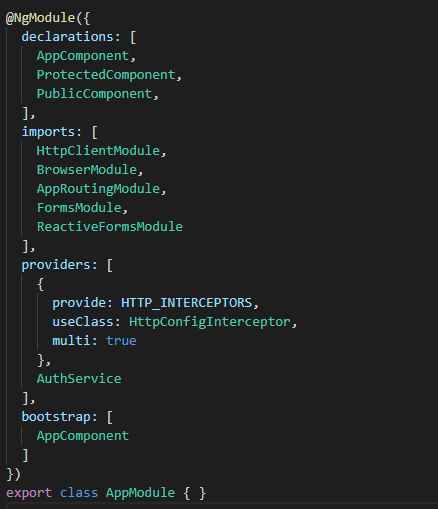
Veamos que tenemos en nuestro «app.module»:
Configuración en AppModule
declarations: Se declaran los dos componentes que vamos a usar en nuestra demo el público y el privado.
imports: Importamos «HttpClientModule» para poder realizar conexiones http, «FormsModule» y «ReactiveFormsModule» para poder crear nuestro formulario de login. Los otros dos imports se añaden automaticamente al generar el proyecto.
providers: Acá estamos registrando nuestro servicio de autenticación y además registramos nuestros interceptor.
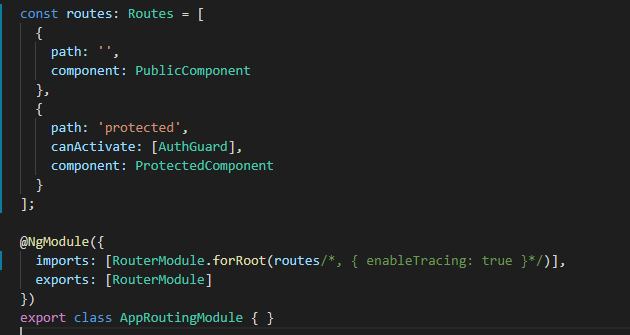
Ahora revisemos el «app-routing.module.ts»:
Configuración del AppRoutingModule
Lo único que debe importarnos acá es el registro de los routes, como podemos ver tenemos un array con dos objetos uno de ellos es nuestro componente público al cual estamos direccionando la ruta por defecto y el otro objeto es para nuestra componente protegido, en el cual es necesario indicar que para activarse (canActivate) se usará nuestro guard que se detallará más adelante.
Rapidamente, revisemos los componentes que se han creado:
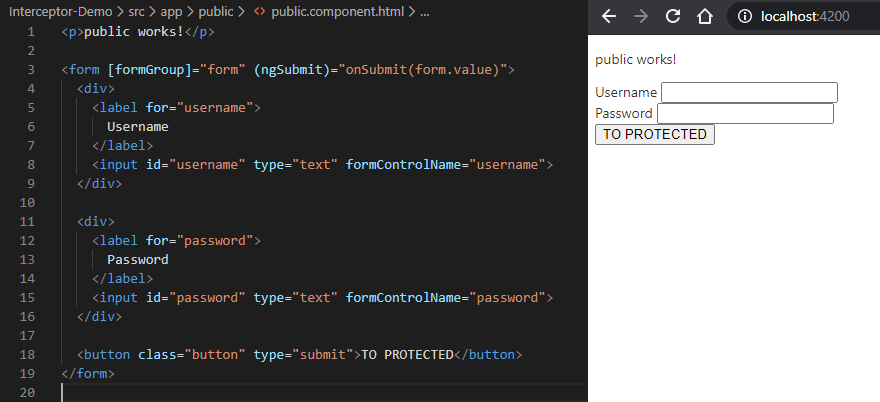
Public
Configuración en el componente publicConfiguración de la vista del componente public
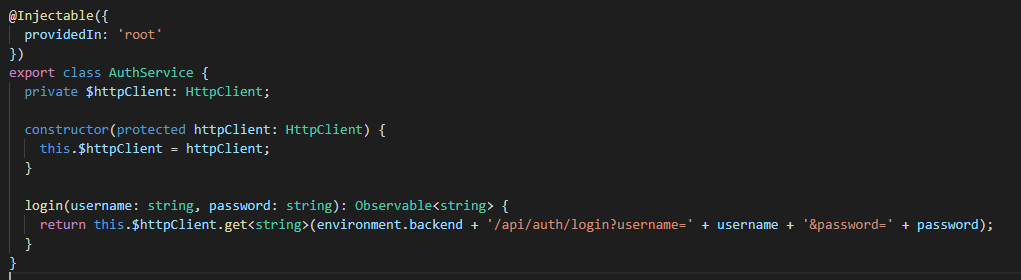
Veamos un que tenemos en este componente. Declaramos un formulario de login típico que al realizar el submit llama al método «onSubmit()», tenemos la inidicalización de nuestro formulario y en el submit se valida si se ingresaron valores de usuario y contraseña y de ser esto así llama al servicio de login. Si este último llamado es correcto nos subscribimos a la respuesta para poder guardar el token en el localstorage y hacemos un navigate con el route a nuestro componente protegido «protected».
Protected
Configuración del componente protected
Este componente es literalmente un «ng g c protected». Dado que la demo se centra en llegar a el, no en lo que este nos va a mostrar. Veamos que sucede cuando en nuestro componente public se ejecuta la linea:
this.router$.navigate(['/protected']);Lenguaje del código:JavaScript(javascript)
Se vemos el código, esta linea se ejecuta si y sólo si la petición que se realizo al backend por el token fue correcta y antes de realizarse se graba este token en el localstorage del browser. Cuando se ejecute, es donde entra a tallar nuestro guard. Veamos que lógica se tiene ahí.
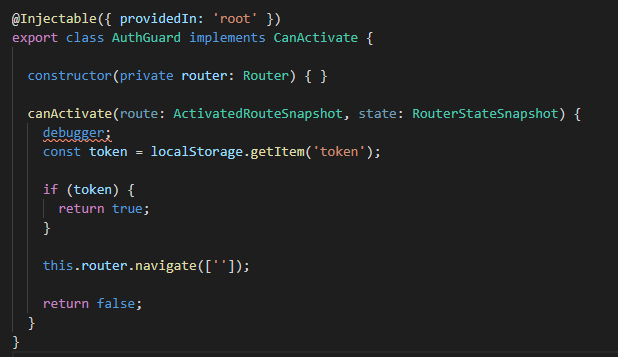
Configuración del guard
Lo que tenemos acá es una clase creada por notros que implemente «CanActivate» y en esta implementación lo que yo estoy haciendo es intentando obtener el token que se debío grabar si la autenticación es correcta, si se obtuviera entonces retorno true y esto hace que angular nos redirija a nuestra url solicitada. De no ser asi, le estoy indicando que envíe al usuario a la ruta básica (public para nuestro caso) y que retorne false.
Revisemos para finalizar el consumo del servicio de autenticación y el interceptor.
Servicio de autenticación
Lo interesante acá es el interceptor ya se explico donde debemos registrarlo, ahora veamos como se ha implementado y que nos permite realizar.
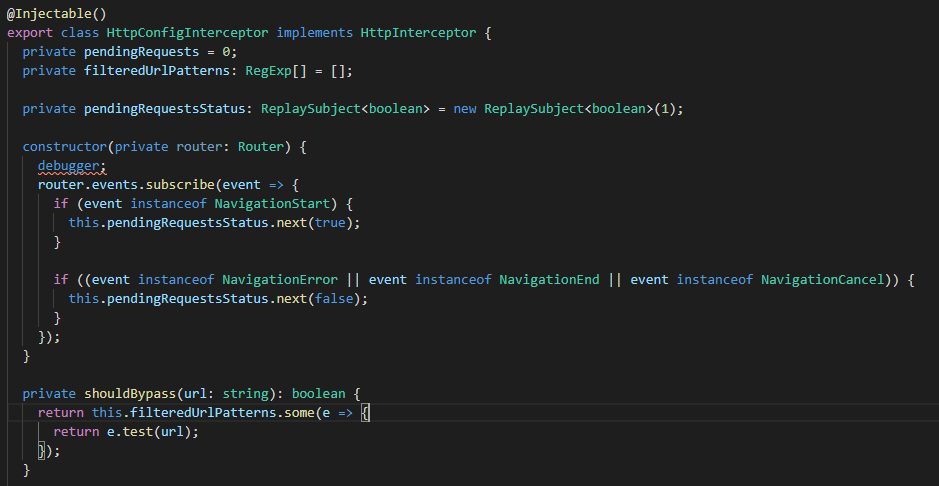
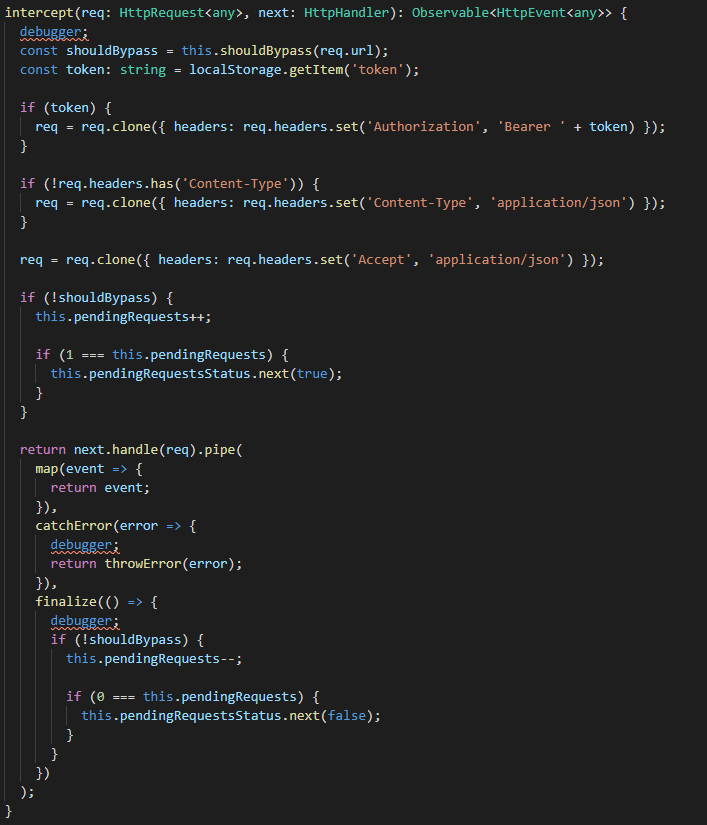
Implementación interceptor parte IImplementación interceptor parte II
Veamos como en el constructor de nuestro interceptor nos subscribimos a los cambios en el route, se valida el tipo de evento y luego se le indica que siga avanzando y termina entrando en nuestro método implementado «intercept» en este método validamos la url que se intenta consumir con una expresión regular, luego de verifica si existiera un token en nuestro localstorage, de ser este es el caso se clona el request inicial y se le añade el header de «Authorization» con el bearer que corresponde. Del mismo modo, se añade el header del «Content-Type» y por úlitmo siempre se añade el header del formato de la data esperada con el «Accept». Además, incrementamos los request pendiente de realizar con el «pendingRequests» y finalmente en el return le hacemos un pipe al observable que va a retornar de la solicitud. Cuando esta solicitud sea exitosa entrará a nuestra subscripción en nuestro componente que ya revisamos previamente, en el caso contrario entrará al «catcherror» y acá simplemente haremos un throwerror. Consideremos que siempre entrará al método «finalize» y es acá donde reducimos nuestras request pendientes por que ya se realizo.
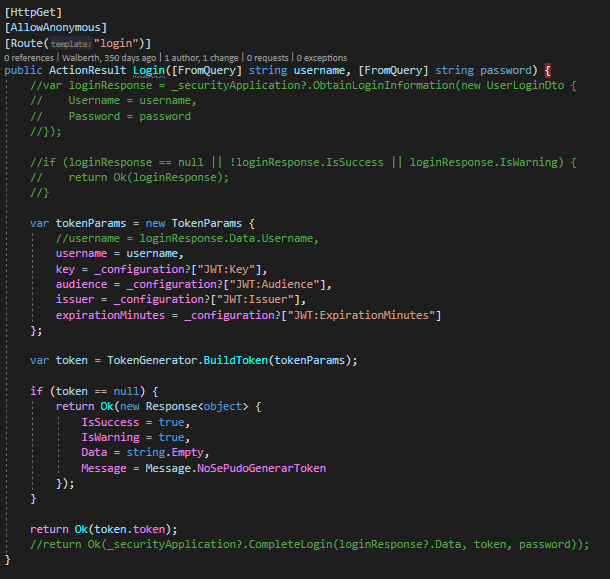
Ya para terminar con este post – ahora si de verdad – veamos que hace nuestro backend.
Backend para generar el JWT
Como se puede observar, se a modificado un poco el funcionamiento del método para que basicamente reciba un usuario y contraseña, genere un token y lo retorne.
Con esto terminamos la demo y aunque el post salio un poco más extenso de lo que hubiera querido, me parece que se cubre todo a detalle. El funcionamiento de la demo pueden revisarla el video que adjunto y como siempre dejo también acceso al repositorio donde pueden encontrar el código fuente del frontend.
Esta semana me toco estar en una reunión donde entre otras cosas se discutía el desarrollo de un nuevo microservicio que permita suplir alguna necesidad del negocio, y mientras se exponían puntos de vista sobre que deberíamos considerar, se tuvo un debate ameno sobre el uso de un ORM para tener acceso a datos en una base de datos relacional. Esto me llevo a querer hacer una demo sobre como funciona entity framework con NetCore 3.0, como se debería configurar para conectar a una base de datos y poder obtener información.
Así nace este post, tenemos un proyecto básico que nos permite conectarnos a una base de datos en MySQL, y que con EF podemos tener acceso a su información. Aproveche para configurar algunas cosas adicionales en el proyecto que también voy a explicar.
Primero quisiera comentar que mi historia con EF, no siempre fue la mejor. Cuando inicie en mi primer trabajo como practicante recuerdo que el sistema que tenían usaba ADO.Net con la ejecución de procedimientos almacenados, y en ese tiempo el lider técnico era un evangelizador de los beneficios que brindaba poder modificar los procedimientos sin necesidad de tener que realizar un deploy de la aplicación. Y asi es como yo inicialmente no tuve mucho contacto con EF, en trabajos venideros empece a aprender más sobre bases de datos, sobre distintos tipos de ORM, y poco a poco me fui interesando sobre el potencial que tenía EF, hasta que llego un proyecto en el que pude verlo en extenso y ser testigo de todo el potencial que esconde, claro con los problemas que también puede acarrear.
Digo problemas, por que si es mal usado puede devenir en un ineficiente manejo de la base de datos, todo depende de como lo usen los desarrolladores y que prácticas se sigan. Ahora si, veamos el proyecto.
Partimos ejecutando el siguiente script de la base de datos, que pueden encontrar en la carpeta scripts del repositorio.
Scripts
Veamos un poco el diagrama entidad relación de esta base de datos de demo.
Diagrama E-R
Como podemos ver, tenemos un diagrama con 12 tablas, entre las cuales de modo básico tenemos el manejo de las direcciones de una persona, y los estudiantes. Veremos más a detalle como se vincula la información en el video. Revisemos, ahora el proyecto.
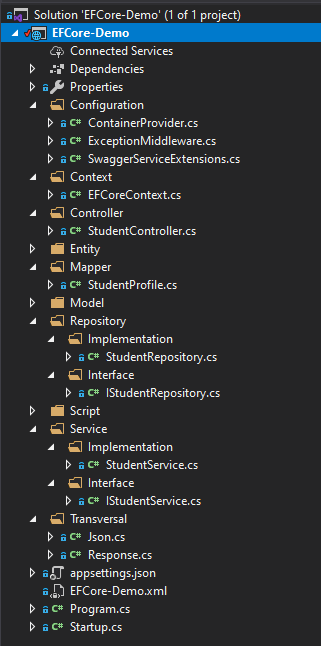
Configuración del proyecto
Repasemos cada una de las carpetas y como se han dividido.
Configuration: Acá he puesto algunos archivos de para el correcto funcionamiento del proyecto, el archivo «ContainerProvider.cs» es para la inyección de dependencia, «ExceptionMiddleware.cs» nos permite capturar alguna excepción no controlada que se pueda generar en la ejecución de la aplicación y centralizar las acciones que tomen y finalmente «SwaggerServiceExtensions.cs» que nos permite realizar la configuración de swagger para generar documentación en nuestra API.
Context: En esta carpeta, se tiene el archivo «EFCoreContext.cs» que nos permite configurar entity framework, las relaciones entre las distintas tablas entre otras cosas.
Controller: Acá irán todos los controladores que necesitemos exponer en nuestra API.
Entity: La entidad que obtendremos de la base de datos.
Mapper: Estamos usando automapper en el proyecto, en esta carpeta pondremos los distintos profiles que requiramos crear para realizar el mapeo de nuestra información.
Model: En esta carpeta pondremos todas los DTO, que se expondrán como información por nuestro API.
Repository: Esta carpeta será nuestro repository, para el cual tenemos la interfaz, y su implementación.
Script: Acá estoy dejando ciertos archivos importantes para poder levantar la demo, el script de base de datos, diagrama E-R, etc.
Service: Acá pondremos la lógica de negocio que consideremos necesaria. También tiene la interfaz y su implementación.
Transversal: Pondremos acá distintas utilidades que podemos usar en el proyecto.
Para no entrar en detalle de la configuración en EF de todas las entidades, tomemos como modelo a la entidad «person».
Configuración de la entidad person
Como podemos ver, nos valemos de las «DataAnnotations» que nos permitan indicar el nombre de la tabla que se va a mapear a una entidad, del mismo modo con las columnas, en caso posean un nombre distinto en la base de datos. Mediante estas anotaciones es posible especificar más información, como las relaciones entre las tablas o las llaves primarias y foraneas que se tienen. Sin embargo, particularmente prefiero indicar estas relaciones en el context.
Veamos que configuración se tiene en este archivo.
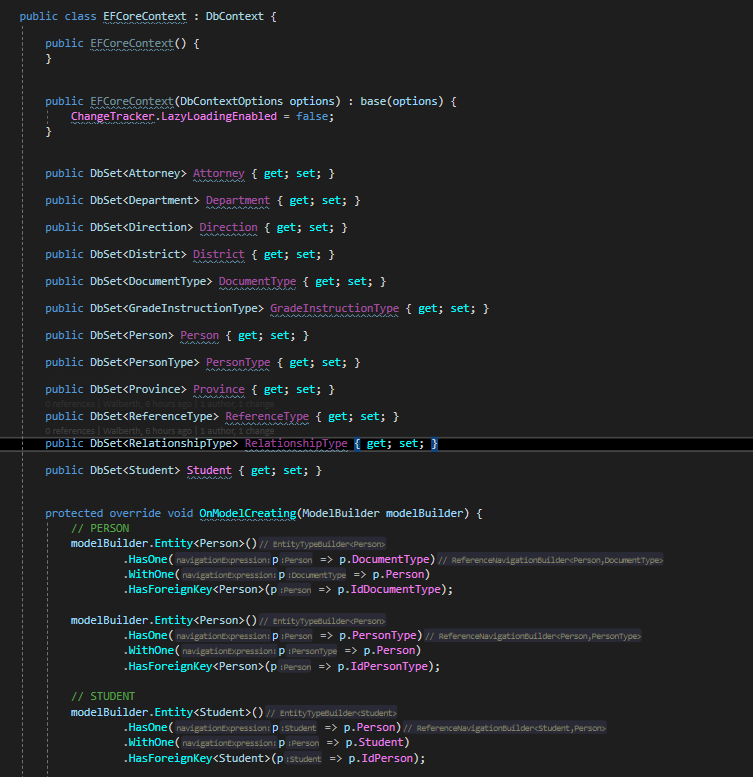
Configuración contexto
Como podemos ver, es necesario realizar un override al método «OnModelCreating» y ahí especificar las relaciones entre las distintas tablas, así como también las llaves foraneas. Entre otro tipo de configuración con la base de datos que sea necesario realizar. Revisemos ahora el repositorio y como estamos obteniendo la información.
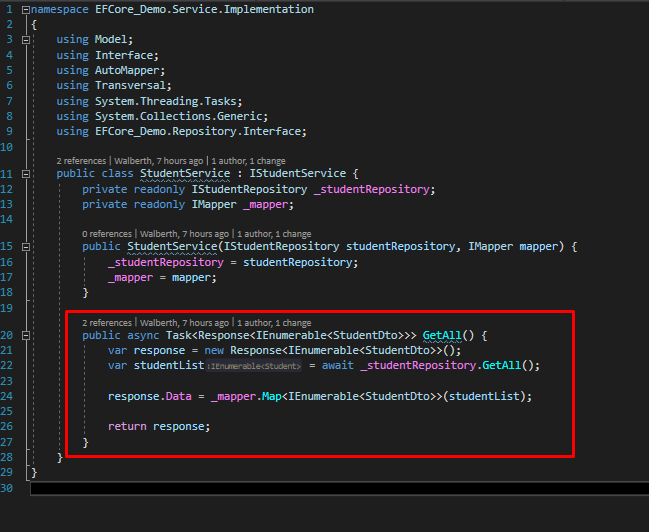
Llamada al contexto
Tenemos una interfaz que declara un método asyncrono que permite obtener el listado de estudiantes y en su implementación hacemos uso de EF para obtener esta información con los joins que son necesarios para nuestra demo. En la capa de servicio, tenemos los siguiente.
Servicio
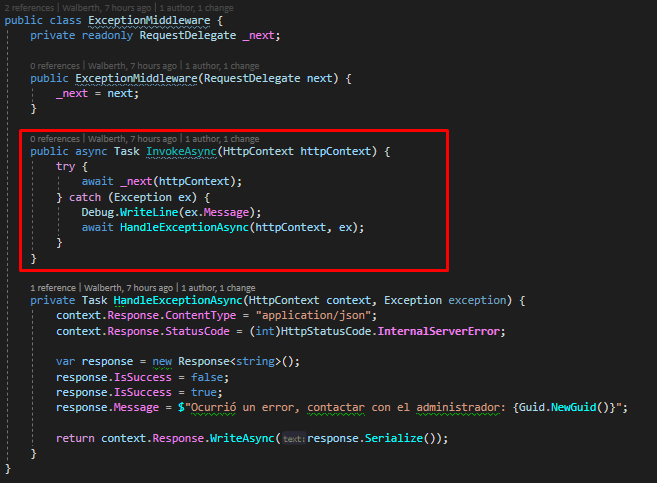
Tenemos la implementación de la interfaz para la capa de servicio, como se puede ver, se obtiene del repositorio la información y luego se realiza un mapping de estos campos para el DTO que terminaremos devolviendo en el API. Notemos que no tenemos ningún try-catch hasta ahora en nuestro código, esto dado que se a implementado un middleware que nos permita centralizar los errores. Veamos como se implemento esto.
ExceptionMiddleware
Si ocurriera algún error en la ejecución de nuestra solicitud, se terminará entrando en nuestro método «HandleExceptionAsync» acá podríamos tomar las acciones necesarias, para la demo estoy devolviendo un error genérico que un GUID autogenerado por cada error.
El proyecto no es nada del otro mundo, con respecto a lo que ya hayamos visto con net core, pero me parecío interesante hacer una guía sobre como usar EF. Pueden revisar el video en donde seguro hablo a más detalle sobre algunas cosas de la implementación del proyecto, el proyecto demo también esta en github por si quieres revisarlo y si hubiera alguna duda adicional pueden dejarme una pregunta.
Hace un tiempo en el trabajo tuve la oportunidad de ser parte de un proyecto que buscaba centralizar el logging de múltiples aplicaciones en una sola y persistir esta información no en una base de datos, sino en uno de los servició que ofrece Amazon Web Services (AWS) para este fin que es CloudWatch. Esto me llevo a todo un proceso de investigación y recabar información sobre la mejor manera de realizar este grabado de log. De ese proceso de investigación nace este post.
Primero, hay que decir que AWS es todo un mundo por si solo, se tienen muchos servicios orientados a necesidades especificas en el proceso de desarrollo de software, asi como también de cara al despliegue de aplicaciones, seguridad, networking, almacenamiento, entre otros. Esto me lleva a comentarles que en adelante intentaré realizar más post sobre los servicios que ofrecen y como se pueden usar, esto obviamente lo hago para compartir la información y también afianzar lo poco o mucho que puedo ir aprendiendo. Vamos al tema en específico, cuando me planteo realizar esta aplicación, que por lo demás tenía claro que era un API en net core, busque que alternativas tengo para comunicarme con AWS y específicamente con cloudwatch, encontrando las siguientes:
SDK de Amazon
Diversas librerias que se integran con aplicaciones de loggers (Nlog, Log4net, Serilog, etc).
Debido al tiempo que tenía para realizar la aplicación y a la experiencia que tenía con las herramientas que tenía a la mano, termine decantandome por usar la librería para Nlog. Esto, por que ya tenía el conocimiento de Nlog, te instala un módulo que le permite tener acceso a cierta información para grabar un log. Sin embargo, esto me trajo algunas complicaciones para el caso de net core que ya más adelante veremos.
Proyecto
La demo, consta de una aplicación web api generada de 0, con lo mímimo necesario apra que pueda funcionar nuestro log en AWS. Las librerías a usar, son las siguientes:
AWS.Logger.NLog (v1.5.1)
NLog (v4.6.8)
Me interesa explicar como se lleva a cabo esta configuración, dado que lo demás es lo típico con cualquier aplicación en net core. En nuestro archivo «Startup.cs» tenemos que realizar las siguientes configuraciones:
Configuración del target en nlog para AWS
Config target
Como se puede ver, se crea una nueva clase del target (que esta disponible luego de instalar la librería) y tenemos que proporciarle cierta información:
Credentials: Se le indica el tipo de autenticación que se va a usar, para la demo he creado en AWS un IAM (manejo de indentidad) que sólo tenga permisos para poder comunicarse con cloudwatch (en otro post voy a ahondar en como AWS maneja la seguridad), existen otras tipos de credenciales, por ejemplo en el trabajo dado que nuestro aplicativo está en un EC2 se puede obtener la autenticación de la máquina.
LogGroup: Cada uno de los log que se graben están asociados a un log group, que digamos que es la instancia que se crea para almacenar todos los logs que provengan de ese cliente.
Region: Es la región en la cual está nuestra cuenta de AWS. Entendamos que esta plataforma esta mundial, y por lo tanto tiene servidores en distintos lugares del mundo, esto debido a buscar que sus servicios sean escalables y redundantes ante cualquier eventualidad y a ti como usuario te permite elegir consumir los servicios que ofrecen en distintos lugares del mundo. De esto también se puede ahondar más adelante.
LogStreamNameSuffix y LogStreamNamePrefix : Cuando se crea una nueva instancia en un log group esta se crea con un identificador único la cual es un GUID más un timestamp, esto es así si no se le proporciona ningún parámetro. En cambio si le pasamos un sufijo o un prefijo ya no se genera el GUID, sino se le concatena a lo establecido (prefijo y sufijo) la marca de tiempo.
Layout: Este punto lo deje al final por que es donde probablemente me deba explayar más. como ven es un texto, pero me estoy valiendo de los layouts renders proporcionados por nlog para obtener cierta información y evitarme tener que obtenerla por otros medios.
Ampliando el último punto, pueden encontrar más información sobre esto en este link.
Una ves que se configura el target de AWS, es necesario indicarle a nlog que debe de usarlo, asociarle los eventos del log y la configuración a logmanager. Veamos como se hace esto en código.
Configuración de nlog
Como se puede ver, se crea el un nuevo «LoggingConfiguration», a este se le asocia el target a aws creado y además las reglas a las cuales estará vinculado nuestro target, finalmente también estoy indicando donde estará el log interno de nlog y le paso toda está configuración a logmanager.
Para cierta información que en teoría debería ser proporcionada por los layout render, pero que parece que en net core no funcionan correctamente, me valí de un Middleware, acá pueden ver que información de obtiene de ahí.
Configuración del middleware
Se está obteniendo la URL que se está consumiendo, el username que consume la aplicación, si se tuviera como header, el método http (PUT, POST, GET, etc). Finalmente, cuando un evento de log (para nuestra demo excepción) se lleva a cabo.
Evento de error disparándose
Disparando el log
Finalmente, veamos nuestro appsettings para ver que configuración tenemos ahí.
Configuración del appsetting
El accesskey y secretkey son las que cree para la demo, este usuario ya ha sido eliminado de mi cuenta de aws.
Realicemos la prueba de nuestra demo para ver si efectivamente tenemos nuestro log en AWS ahora. Primero tomemos algunas capturas del ambiente antes de ejecutar nuestra demo.
Log Groups en AWS
Listado de log groups
Postman
Get request
Levantamos la solución (con lo que nuestro log group ya debería haberse creado en AWS) y realizamos la solicitud al api.
Entro a la excepciónEsta por enviarse el log a AWSRespuesta en postmanValidamos que se creo nuestro log groupValidamos nuestro log streamEl log grabado
Como podemos ver (si hacemos zoom) nuestro log se ha grabado correctamente en AWS.
Con esto llegamos al fin del post, dejo el link al repositorio donde está el código fuente por si quieres revisarlo y un video de la demo.
En este post, me dedicaré a explicar que buenas practicas en logging se deben seguir cuando desarrollamos una aplicación web, que quede claro que este es un enfoque personal, que he podido formular con cierta experiencia.
Por otro lado, es necesario comentar que si bien es cierto el ejemplo en cuestión, lo voy a realizar usando Spring boot, la información que se debe obtener para enriquecer el log, puede variar de acuerdo a la tecnología que se va a usar (Net Core, Framework, Node, etc).
Empecemos primero, explicando un poco sobre los niveles de logging que se tienen y en qué caso es necesario usar uno u otro.
Niveles de Logging
Como se puede ver en la imagen, el logging no solo sirve para capturar errores (lo cual es fundamental en el proceso de desarrollo y para el posterior soporte a las aplicaciones), sino también para determinar que feature es el más usado, información de configuración de la aplicación, entre otras.
Por otro lado, el logging se puede desarrollar en múltiples appenders (este nombre es usado en log4j o log4net), como una buena práctica es necesario que como mínimo se realice el grabado del log en dos appenders, siendo una de estos la base de datos y el otro un archivo de texto, en una ruta en específico (pudiendo ser dentro de la solución desplegada). Basicamente en este post me enfocaré en explicar la información que se debe guardar en un log de error (FATAL y ERROR). La información que vamos a considerar es la siguiente:
Fecha y hora del log
Nivel del log (FATAL, WARNING, etc)
Mensaje
Stack de la excepción
Payload (en caso que la consulta sea un GET, DELETE se debe obtener la información enviada en el url, de ser un POST, UPDATE, PATCH El body)
Callsite (el endpoint que es consumido que en el cual se termina generando el error)
La acción bajo la cual se produce el error (nombre del método en el controlador)
El usuario con el cual se produjo el error.
El nombre del método en el cual se generó el error (de la capa de lógica de negocio)
El nombre de la aplicación en la cual se generar el error (varía de solución en solución)
Claro, que de acuerdo a qué librería se este usando para realizar este grabado del log es posible tener todo tipo de appenders, uno que me llama mucho la atención es el que nos permite enviar esta información a herramientas como elastic search y luego al integrarlo con otras herramientas como grafana para generar reportes.
En nuestra aplicación demo, nos valdremos que ciertas características del framework para poder tener acceso a la información antes detallada.
HandlerInterceptorAdapter
Al implementar esta clase abstracta y hacer un override al método preHandle tenemos acceso en el pipeline del framework, además de anotarla como «Component». Como podemos ver en la siguiente imagen.
Implementación del override del preHandle
Como podemos ver, nos valemos del HttpServletRequest para tener acceso a mucha información necesaria para enriquecer nuestro logging, detallemos cada uno de los puntos que nos servirán:
La url a la cual se está consultando la obtenemos con el método «getRequestURI».
Para obtener el nombre del método, nos valemos de una pequeña lógica que obtiene el indice del último luego del «/» y con esto hace un substring para poder obtener el último texto.
Para el hostname de la máquina, nos valemos de la librería «java.net.InetAddress».
Es necesario validar si la petición es del tipo «GET» para de este modo obtener los query params que se esten enviando. Si este fuera el caso usamos «getQueryString» para este fin.
Obtenemos un parámetro denominado «username» que se está enviando en cada una de las peticiones, sea cual sea el método http, esto con la finalidad de guardar el usuario al cual está vinculado el log. Para esto tenemos opción de guardarlo en sesión en el caso nuestra solución sea del tipo MVC, pero al tener un Web API no es posible. Podrían usar un interceptos en angular (de ser este su caso) para que a cada una de las peticiones le adicione este parámetro.
Con esto, cubrimos en cierto aspecto la información que necesitamos para nuestro logging. Sin embargo, tenemos que considerar también las solicitudes http del tipo POST, y que por lo tanto tienen un body.
RequestBodyAdviceAdapter
Nos valdremos de esta clase abstracta, y especificamente en nuestra implementación haremos el override de «supports» y de «affterBodyRead» como podemos ver en la siguiente imagen:
Override de métodos en la implementación de HandlerInterceptorAdapter
Además, es necesario decorar la clase con la etiqueta «ControllerAdvice». Veamos que información obtenemos de este método:
El payload del body, el cual obtenemos del Object que se recibe de «afterBodyRead», en mi caso se hace un «toString» dado que en las clases implementadas se está haciendo un override a esté metodo para darle la forma de json, como podemos ver en la siguiente imágen.
Override del «toString» en la clase
Además, es muy importante en nuestro logging tener grabadas en nombre del método en el cual se realizo la caída del sistema. Este método puede estar en el stack de la excepción, pero para tenerlo directamente me estoy valiendo de una característica propia del framework, la cual se denomina «aspects» en spring, en algún otro post me dedicaré a explicar los tipos que hay y como se ejecutan en detalle, en este post sólo presentaré como se están usando.
Aspects
Spring nos brinda una herramienta muy potente, la cual es denominada programación orientada aspectos, lo cual en pocas palabras, puede facilitarnos la vida en múltiples escenarios y evitarnos repetir código innecesariamente. Veamos la siguiente imagen:
Implementación de un aspecto
Se creo un aspecto y se decoro con las etiquetas «Aspect» y «Component» para que se registre por el framework, lo que nos permite un aspecto es que esta sección de código de ejecute en ciertas condiciones. Para el caso, se llevará a cabo en la siguiente sintaxis:
Lo cual nos indica que el aspecto coberturará todos los métodos que se encuentren en el paquete «implementation» que tengan cualquier nombre (veamos los *.*), que tengan cualquier tipo de entrada (veamos los dos puntos dentro de los paréntesis) y el asterisco inicial, indica que coberturará cualquier tipo de devolución. Como variable de entrada de nuestros aspectos tenemos a la clase «JoinPoint», la cual posee varia información interesante, para lo que necesitamos usaremos «getSignature().getName()» que nos brinda el nombre del método en el cual se registra el error y el cual llama nuestro aspecto.
Finalmente, para realizar el grabado del log y generar un identificador único del log, el cual debe ser proporcionado al usuario del aplicativo. Para esto, usamos algo que ya se explicado antes. Un «ControllerAdvice», el cual actua como interceptor de los errores.
Finalmente, veamos como queda nuestro registro del log.
Divido la fila asi, para que se pueda visualizar mejor.
Finalmente, puede visualizar el video correspondiente a este post, donde se detalla paso a paso el funcionamiento de la aplicación, así como su prueba consumiento las APIs desde postman.
Espero que les haya sido de ayuda, como siempre dejo el código del proyecto en el repositorio.
Hace poco tiempo participe en una hackaton con unos amigos, y cuando empezamos a desarrollar ya la aplicación luego de haber analizado lo que se buscaba solucionar, yo me valí de una plantilla en spring que había estado trabajando en mi tiempo libre, era la primera ves que la ponía a prueba en un escenario real y el sentido era que ahorraramos tiempo en configurar cosas que siempre son necesarias en todos los aplicativos. Para resumir un poco esta parte, la plantilla se porto como debía. Esta experiencia me lleva a realizar este post, en el que voy a explicar como se configura spring security y la autenticación en base de datos, además de que configurar para poder usarlo con una aplicación SPA del lado del frontend, como puede ser Angular, React, Vue.js entre otras.
Como deben de saber spring security es la librería de spring que nos brinda una visión dogmática de como se debería de implementar la seguridad en una aplicativo. Esto, claro siguiente todo un marco de buenas prácticas que muy probablemente si quisiéramos implementarla de 0, tranquilamente puede ser un proyecto entero sólo para esto. Gracias a esto, es que nos permite ahorrarnos mucho tiempo y nos brinda la seguridad de que estamos siguiendo un marco de buenas prácticas. Para nuestro caso, usaremos json web token (jwt) el cual es una de las alternativas que tenemos para implementar la autenticación.
Nuestra aplicación demo consta de distintas capas, ampliamente explicadas en post anteriores, tenemos un archivo de configuración «application.yml», en la sección «security» hemos definido cierta información importante, entre las cuales está:
La url del enpoint de autenticación.
El tiempo máximo de expiración de un token.
La llave secreta que se usará para poder generar el JWT.
Se ha definido un paquete de configuración, y dentro de este un paquete de jwt, en el cual se tienen distintas clases necesarias para configurar, como es obvio en el pom del archivo se están añadiendo las dependencias de spring security.
Dependencia en el POM
Clases de configuración
Tenemos un controlador llamada «SecurityController», en el cual tenemos los diferentes endpoint:
Authenticate [POST]: Nos permite iniciar sesión en el sistema, retorna el token.
Refresh [GET]: Permite refrescar el token que se ha generado, antes de que expire.
Create [POST]: Permite crear un usuario.
Tenemos en la capa service de nuestro aplicativo un «SecurityService» que es donde se realiza la lógica necesaria para autenticarse, refrescar el token y el crear un nuevo usuario, Por otro lado, en el repository, respetando el principio de single responsability tenemos tres clases (Person, Session y User) para el acceso a la base de datos.
El esquema de base de datos que vamos a usar es el siguiente:
Modelo E-R usado
Vamos a usar una clase a modo de helper, donde tendremos varios métodos utilitarios que nos van a permitir obtener información del token que generemos e incluso generarlo. Esta clase se llamará «JwtUtil».
Métodos en JwtUtil
Luego es necesario crear una clase que extienda de «OncePerRequestFilter», en el cual podamos hacer un override al método «doFilterInternal», en le cual haremos un filtro a las peticiones que recibamos para determinar si poseen token o no y que acciones se deberían tomar. Esta clase la llamaremos «JwtTokenAuthorizationOncePerRequestFilter» y luego veremos donde debemos configurarla para que este filtro se lleve a cabo.
Clase JwtTokenAuthorizationOncePerRequestFilter
También es necesario crear un clase que extienda de «AuthenticationEntryPoint» para poder hacer un override del método «commence», el cual será llamado cuando se determine que ser esta intentando acceder a un endpoint que requiere que se le pase un header de authorization. Esta clase, llevará el nombre de «JwtUnAuthorizedResponseAuthenticationEntryPoint».
Finalmente, toda la magia ocurre en nuestra clase SecurityConfiguration, la cual extiende de «WebSecurityConfigurerAdapter», en esta realizamos múltiples configuraciones que son propias de spring security, Entraremos al detalle de algunas en el post, pero en el video me daré más tiempo para explicar la configuración de esta clase. Uno de los override es al método «configure», considerando que este método en la clase de la que estamos extiendo tiene varios overloads, el que explicaré en el post es el que posee como parametro de entrada un «HttpSecurity», en debemos realizar las siguientes configuraciones:
Deshabilitar el CSRF
Indicar que authentication entrypoint (acá usamos nuestra entrypoint personalizado).
Indicamos que no usaremos sesiones, esto cambiando la configuración de «sessionCreationPolicy».
Configuramos el CORS, para que permita todos los tipos de peticiones (GET, POST, DELETE, UPDATE, etc).
Añadimos el filtro que personalizamos anteriormente, esto con el «addFilterBefore».
Como se puede ver, se nos ha generado un token, si vamos a una página como jwt.io y ponemos el token que ha sido generado, tenemos la siguiente información:
Información del token generado
Los métodos de refresh y creación, pueden verlos a más detalle en el video que como de costumbre cuelgo con los post. Espero que les haya sido de ayuda, si tienen alguna duda les dejo el correspondiente repositorio en github, y los medios de contacto correspondientes.
El penúltimo principio del que nos toca escribir hoy es el de la segregación de interfaces. El corolario de este principio nos indica lo siguiente:
Los clientes no deberían ser forzados a depender de métodos que no vayan a usar.
El problema que se tiene con las grandes interfaces podemos verlo claramente en la clase MembershipProvider que usaba microsoft hace algún tiempo.
MembershipProvider de Microsoft
Hace un tiempo, microsoft sólo soportaba SQL Server como provider, por lo que si se necesitaba usar algún otro provider, era necesario implementar todos los métodos que pueden ver en la imagen.
El resultado de violar este principio, nos lleva a no implementar completamente las interfaces, dado que no es necesario usar todos métodos, esto hace que poco a poco empecemos a adquirir en nuestro código más dependencias, lo cual es muy probable que nos termine ocasionando las siguientes complicaciones:
Más acoplamiento.
Código más frágil.
Más dificultas de probar el código.
Más dificultas en los pases a producción.
Básicamente, lo que nos indica es que debemos evitar crear interfaces con demasiados métodos. Esto lo conseguimos separando las responsabilidades de nuestra interfaces. Para poder determinar si en nuestros proyectos estamos violando este principio, es necesario buscar grandes interfaces, una muestra clara la podemos ver si en nuestro código encontramos algún método que implementa una interfaz y una de estas implementaciones tienen un «NotImplementedException».
Respetar Interface Segregation Principle
Si se diera el caso en que tenemos refactorizar un proyecto para que se respete este principio, podemos considerar las siguientes estrategias, sea cual sea el caso en el que nos encontremos.
Romper una interfaz grande en pequeñas (siempre y cuando nosotros tengamos control de las interfaces a refactorizar).
Si se diera el caso en el que dependemos de una gran interfaz (entiéndase un caso como la implementación del provider indicado lineas arriba), lo que se debe hacer es mediante el patrón adapter segregar las interfaces que necesitemos, y sólo este adapter conocerá todos los métodos de la interfaz que queremos disminuir.
La demo que desarrollare para demostrar lo mencionado en este post, consta de una clase que llamaremos IMachine, que es el simil de una impresora multifuncional.
Interfaz IMachine
Si queremos implementar esta interfaz en un método que sólo imprima, nos veremos en la siguiente situación.
Implementación de IMachine, sólo para imprimir
Con métodos que no necesitamos, por esto se crea una interfaz para cada una de las acciones «IFax», «IPrint» y «IScann». Del mismo modo, si se requiriera que nuestro equipo escanee y también imprima, podríamos crear una interfaz que herede a su ves de estas dos interfaces, del siguiente modo:
Herencia entre interfaces
Como ven, no se esta generando ningún método dentro, dado que el IScan y el IPrint, ya tiene sus implementaciones propias. Así mismo, cuando hacer la implementación de nuestra interfaz IMultiFunction, podemos valernos del patrón decorator para no implementar nuevamente los métodos de imprimir y de scan, sino usar los que ya existen en estas interfaces.
Aplicación del patrón decorator
Espero que con este post se tenga un poco más claro el concepto que nos brinda este principio. El último principio que compone SOLID es el ded la inyección de dependencia, y este lo estaremos revisando probablemente en el siguiente post. Como siempre, dejo el video del desarrollo del post y el link al repositorio en github.
Desde hace algún tiempo que vengo trabajando con Angular, recientemente en un freelo me vi en la necesidad de hacer la carga de un archivo a un controllador en net core. Actualmente en este proyecto se esta usando Angular Material y me di con la sorpresa que en esta librería no se tienen ninguna alternativa a un input type file.
Luego de buscar un poco y no encontrar una alternativa que me llamara la atención, decidí ver la forma de crear una. Les comparto esta demo por si a alguien le puede resultar útil.
Primero, necesitamos crear nuestro nuevo proyecto en angular, instalar la librería de angular material, crear el componente para cargar el archivo y finalmente, crear un modulo adicional para que concentre todos los módulos correspondientes de angular material, para esto ejecutamos en la consola del vscode los típicos comandos:
ng new UploadFileAngularMaterial
cd UploadFileAngularMaterial
npm install --save @angular/material @angular/cdk @angular/animations
ng g m /modules/material
ng g c file-uploadLenguaje del código:JavaScript(javascript)
Del lado de la configuración del angular material, no me explayaré mucho dado que hay muchos tutoriales en la red que pueden dar más ejemplo y también puede verlo en el repositorio al final del post.
Para usar los material icons, estoy en el index de la aplicación poniendo el link a la url:
<linkhref="https://fonts.googleapis.com/icon?family=Material+Icons"rel="stylesheet">Lenguaje del código:HTML, XML(xml)
Veamos ahora si lo importante de esta demo:
File-Upload
El html del componente tendrá la siguiente estructura:
HTML del componente File-Upload
Como se puede observar, tenemos un botón para hacerla carga (una imagen), y debajo de este una lista de los archivos que queramos cargar, en la cual se muestra el nombre del archivo, una barra de progreso, y dos iconos que actúan a modo de botones para reintentar en caso la carga no se haya podido efectuar y para cancelar la carga. Finalmente, nuestro input type file.
Sólo explicaré los métodos más importantes del componente dado que se tienen creado varios:
Variables del Componente
Para nuestro componente, tenemos algunas variables que pueden ser input del componente, y un output del tipo string. Además, la información que se selecciones los ‘files’ so del tipo ‘FileUploadModel’, paso a detallar lo que contiene este model.
Model FileUploadModel
Este modelo posee cierta información que usaremos para manejar la carga del archivo, los estamos que tiene, si se puede re-intentar o cancelar así como las subscripciones que se realizan cuando se hacen las peticiones http.
onClick al botón
Cada ves que se realice un click al botón, se está obteniendo el input type file y se busca el evento ‘onchange’, mediante el cual se obtiene los items seleccionados (archivos de texto para el demo). Dado que el evento ‘onchange’, se va activar cuando este cambie, se llama al evento ‘click’ para que abra el buscar de archivos desde el navegador, de manera que cuando estos sean seleccionados se carguen los archivos, y recién se llama al método ‘uploadFiles’.
uploadFiles
Se empieza a iterar sobre los archivos seleccionados que se llenaron en el evento ‘onchange’ y cada uno de estos estos serán enviados al método ‘uploadFile’.
uploadFile
Este es el método que se encarga de hacer la carga del archivo, para la demo estoy usando un api pública «http://file.io» que te permite realizar la carga de archivos. También se podría llamar a algún service de ser necesario o el modo en le cual deseen consumir servicios desde su aplicativo. Acá, estamos inicializando un HttpRequest del tipo post, y asignado el request a nuestro ‘sub’ que es parte de nuestra entidad. Adicionalmente, vamos a mapear un evento para poder determinar el avance del progress conforme se va cargando el archivo, tenemos una suscripción para manejar lo que nos retorne la suscripción en caso de que la respuesta HTPP sea del tipo 200, si fuera alguna respuesta HTTP de error, entrará a nuestro ‘catchError’. De ser correcto, limpiamos el archivo y le enviamos la respuesta al output del tipo eventEmitter, al componente que este llamandonos. Veamos una demo de como se está dando todo este proceso:
Presionamos el botónLuego de seleccionarlo, se carga al array de archivos y se envia al uploadfilesEsta por llevarse a cabo la solicitud al endpoint
Mientras el archivo carga, se ve la barra de carga, nombre del archivo y un botón de cancelar
Cuando cargo correctamente, se elimina el archivo del listado y se envía el output
Se envia a un console.log el resultado del envio del archivo
Si quisieramos revisar si la carga fue correcta, podemos abrir el link que se adjunta en el response, teniendo el siguiente resultado.
Respuesta del endpoint
Aún cuando el dedsarrollo del componente me tomo mas tiempo del que hubiera deseado, es una buena idea tenerlo como una herramienta más en el repertorio. Dejo un video de la creación del proyecto y las pruebas que se han realizado, además del link al repositorio.