Hola, en un par de post anteriores les explicaba como dockerizar un entorno de trabajo:
Hoy quiero explicarles como podemos desplegar nuestro api (para este ejercicio en NetCore 3.1) en AWS Lambda, usando un AWS API Gateway para poder consumir los recursos.
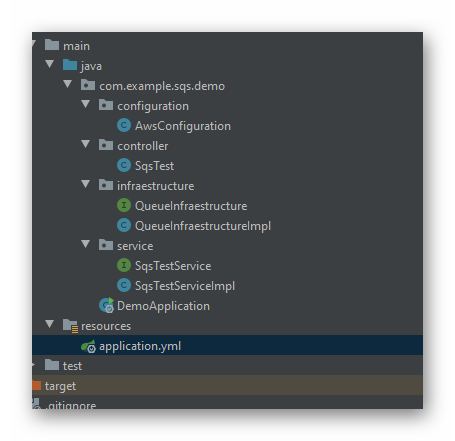
Empezamos en nuestra aplicación en visual studio.
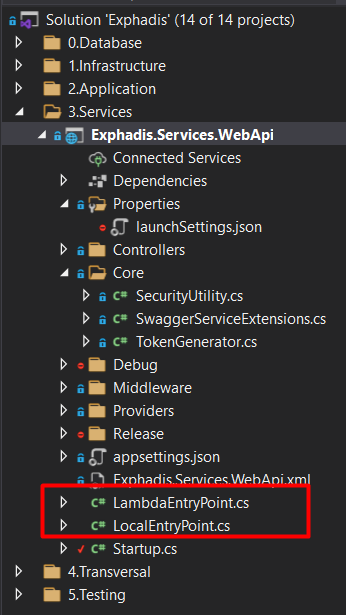
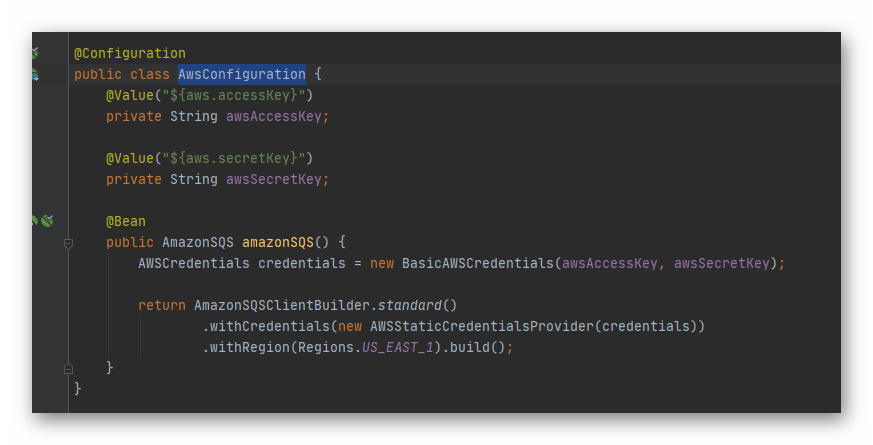
Notemos que en esta aplicación hemos modificado nuestro archivo «Program.cs» y los hemos renombrado «LocalEntryPoint.cs» y además hemos añadido un archivo «LambdaEntryPoint.cs». Sobre el primer archivo no entrare en detale por que es el tipico archivo que tenemos cuando creamos un api en netcore. Pero el segundo si nos interesa, dado que ese es el handler que usará nuestro lambda. Veamos entonces, que nos encontramos.
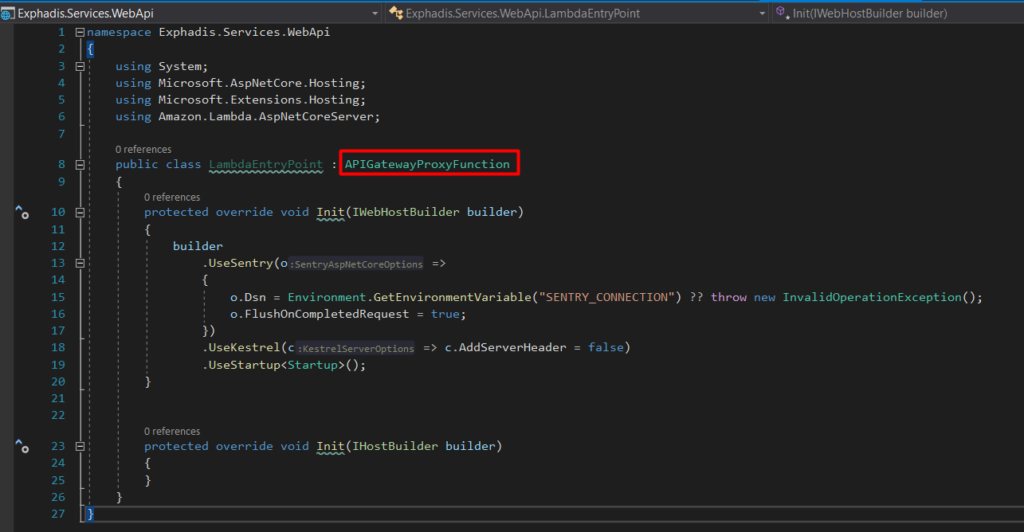
Este archivo hereda de «API GatewayProxyFunction», veremos más adelante que se usa un método dentro de esta clase para el handler, por lo demás estamos usando el overload de uno de los «Init», especificamente el que tiene como entrada un «IWebHostBuilder» que es una interfaz ya conocida. Ahora vemos que tenemos que hacer en AWS. Como nota aparte, les comento que las demos las estoy usando la web de AWS. Sin embargo, todo esto puede ser reemplazada por la configuración desde la consola para crear los recursos y conectarlos entre si. Sin embargo, pienso que las demás son más dinámicas de este modo.
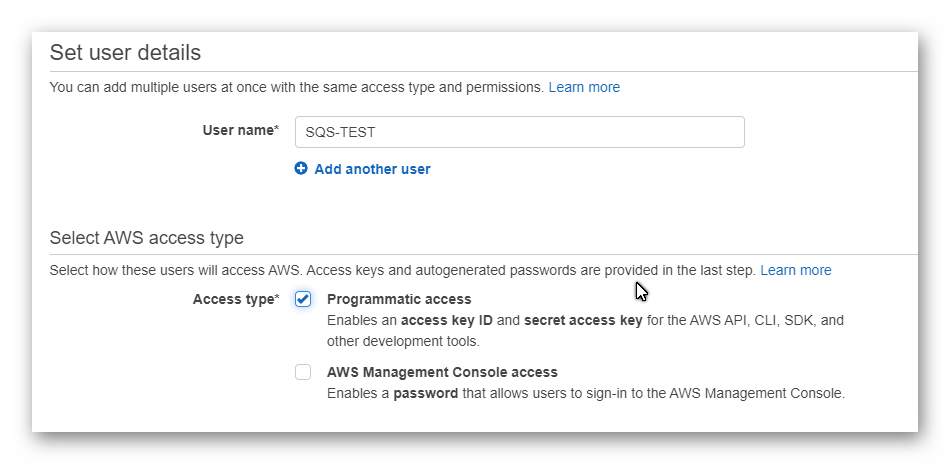
CREACIÓN DEL LAMBDA
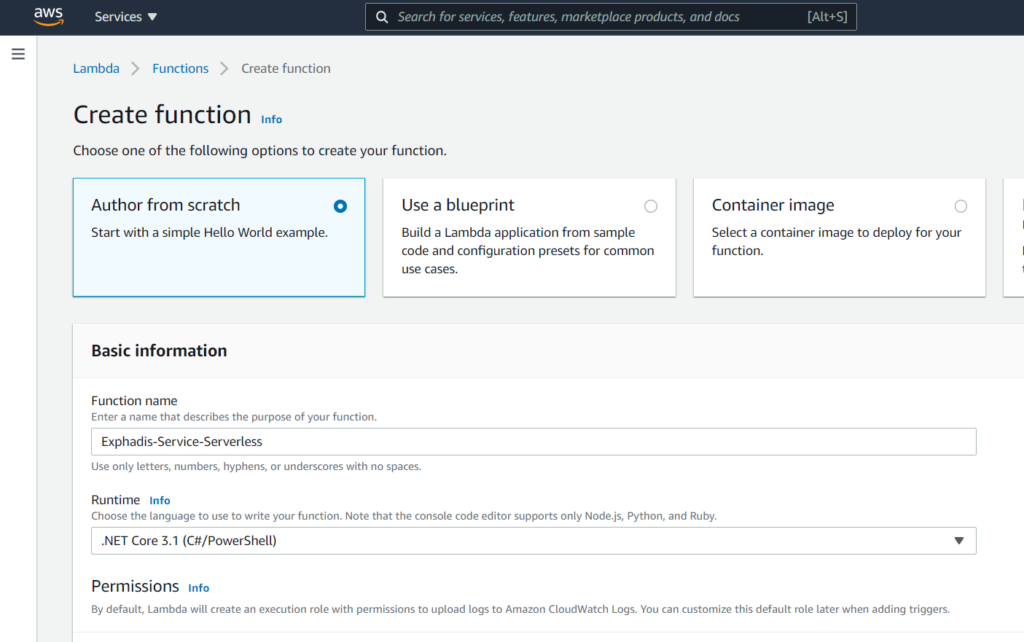
Configuramos el handler

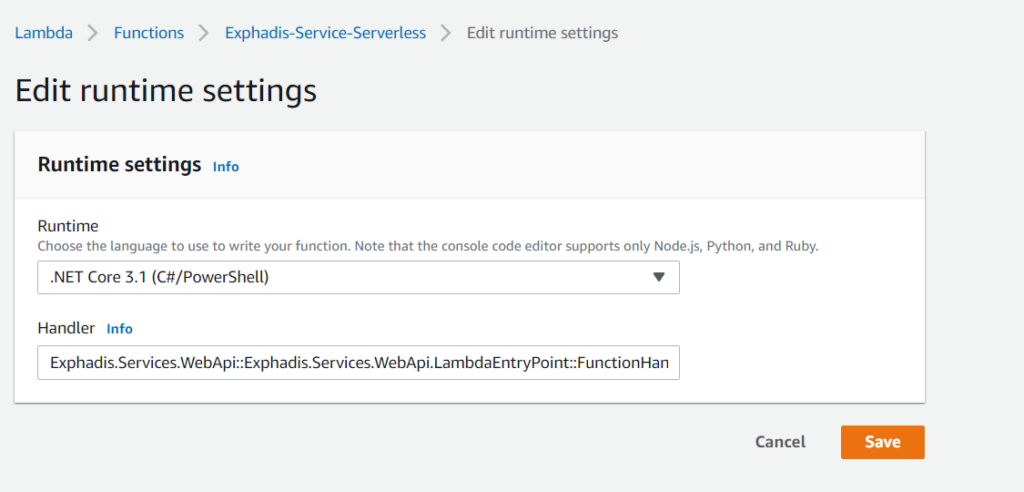
El handler que vamos a usar, se configura del siguiente modo.
Exphadis.Services.WebApi::Exphadis.Services.WebApi.LambdaEntryPoint::FunctionHandlerAsyncLenguaje del código: CSS (css)Donde, el orden es el siguiente:
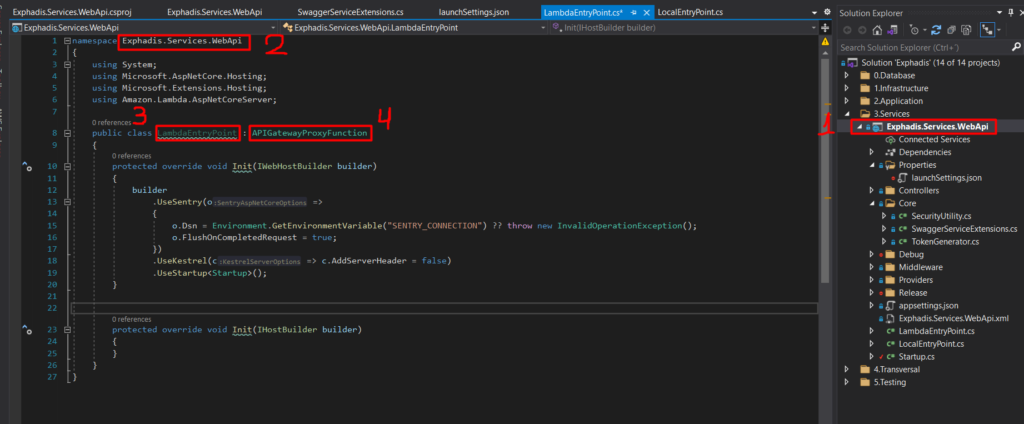
- La ruta del proyecto en la cual esta ubicado
- El namespace de nuestra clase
- El nombre de la clase
- Un método dentro de la clase de la cual estamos heredando
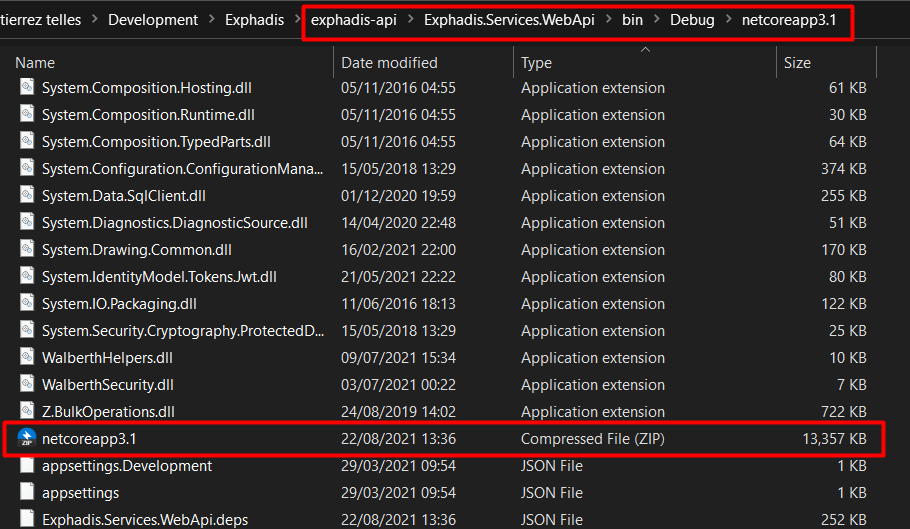
Subimos nuestro código fuente
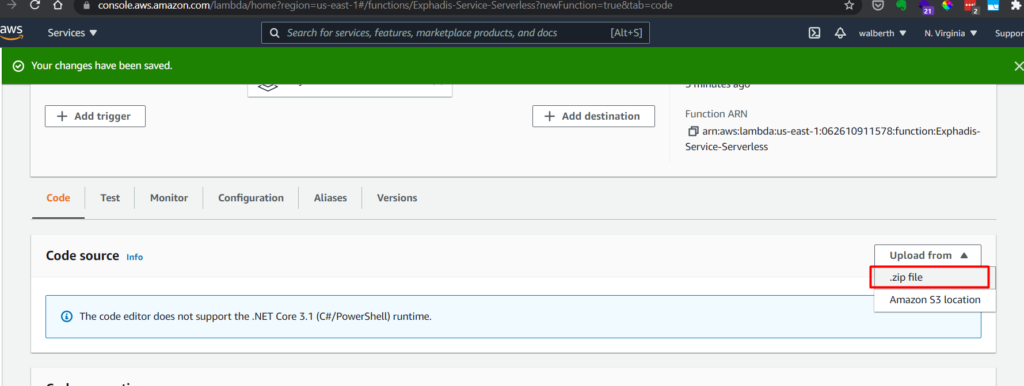
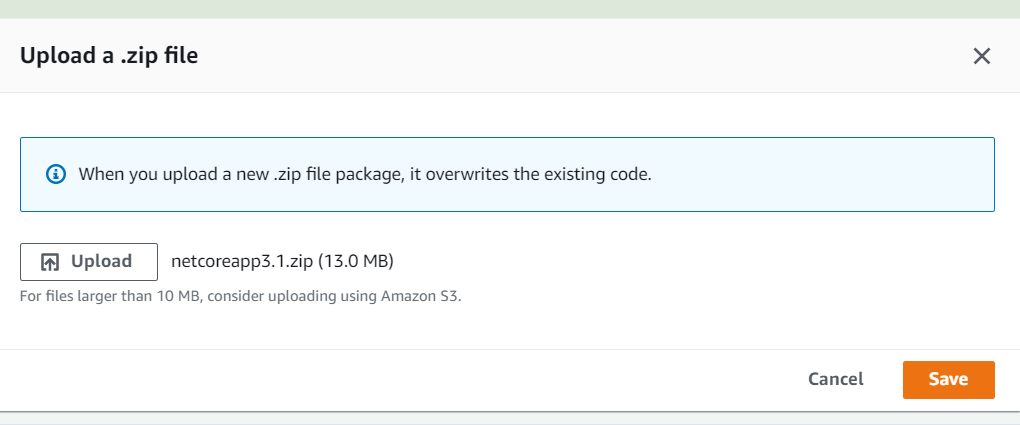
CREACIÓN DEL API GATEWAY

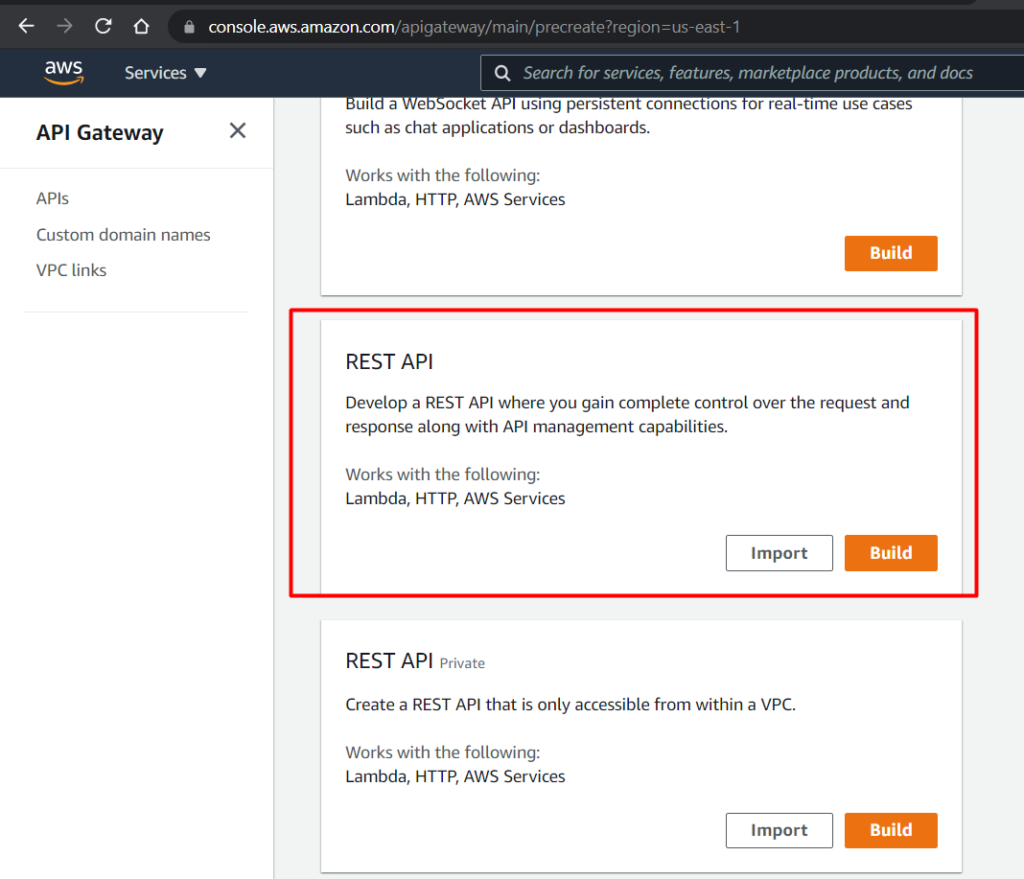
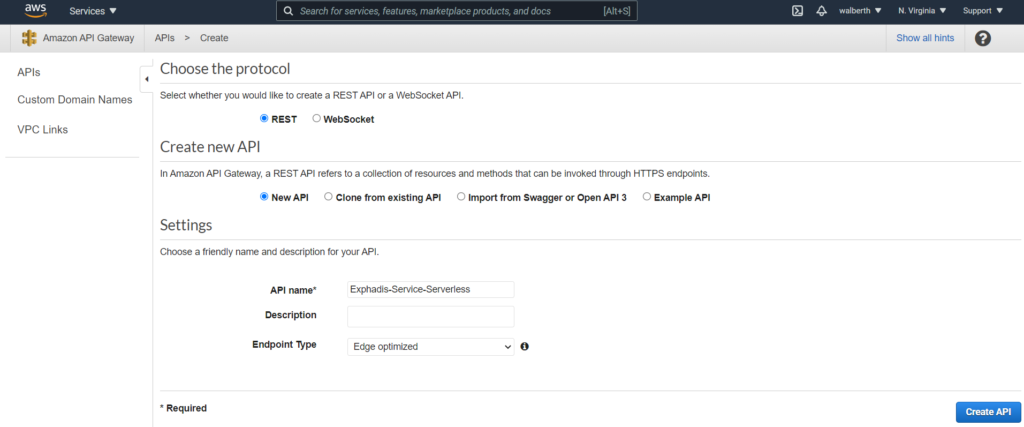
Vamos a configurar nuestro API Gateway para que consuma los recursos de nuestro lambda.
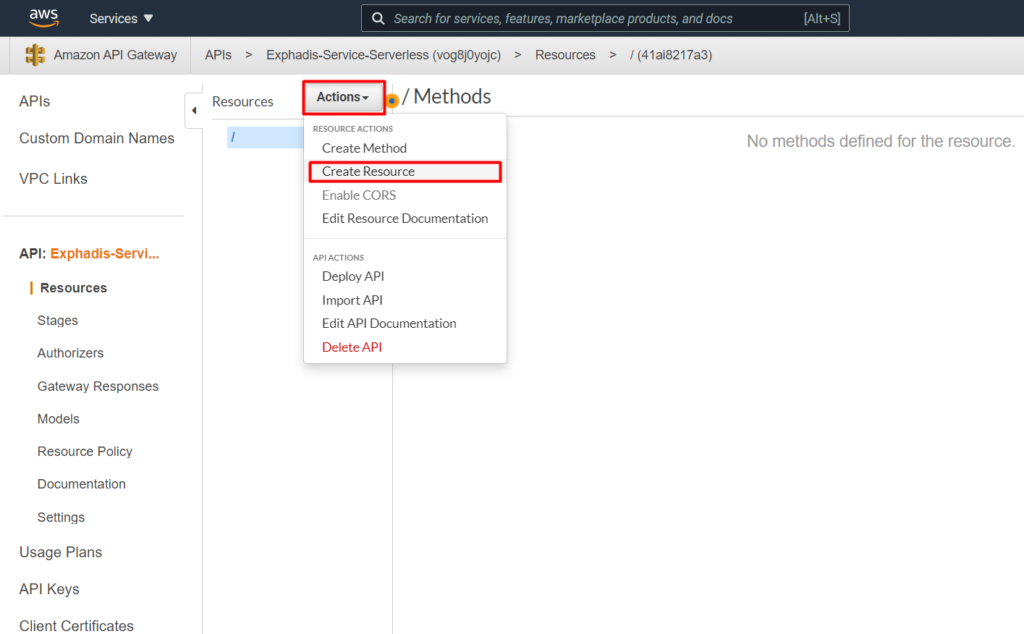
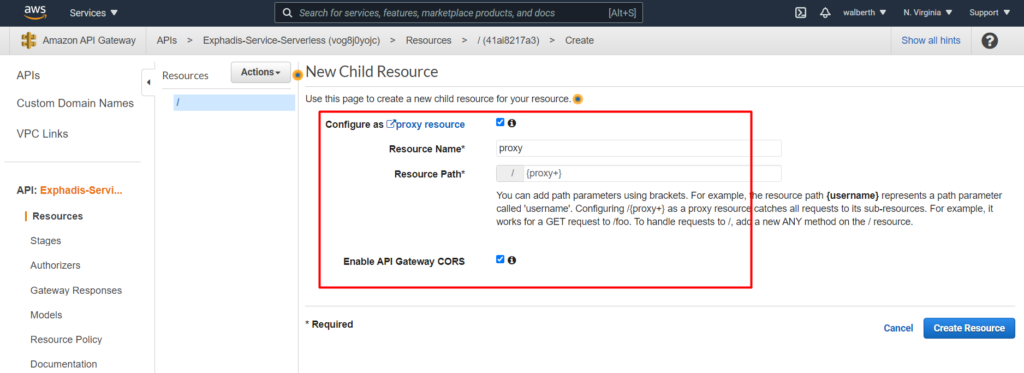
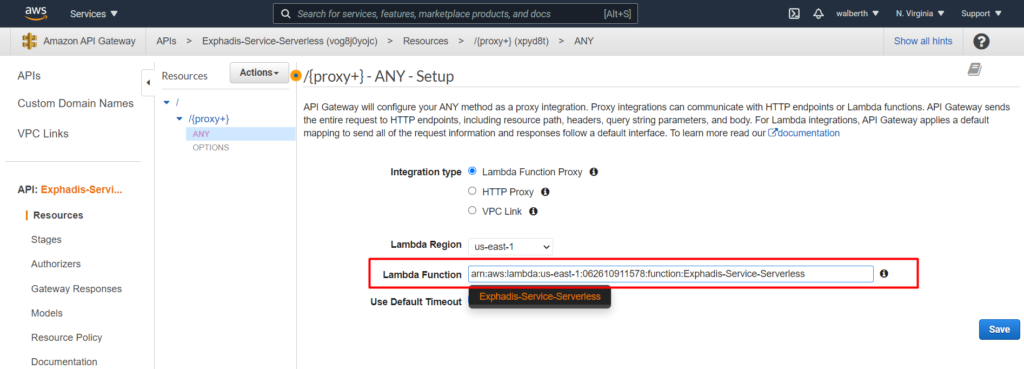
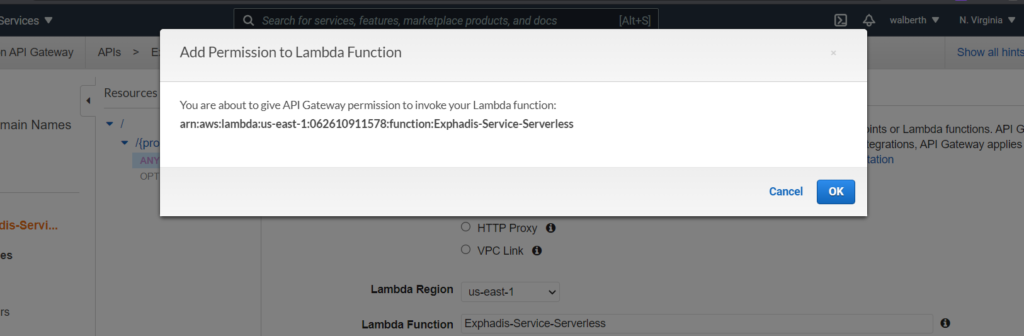
Mapeamos el ARN de nuestro lambda en el api gateway y aceptamos que nuestro api gateway pueda consumir nuestro lambda.
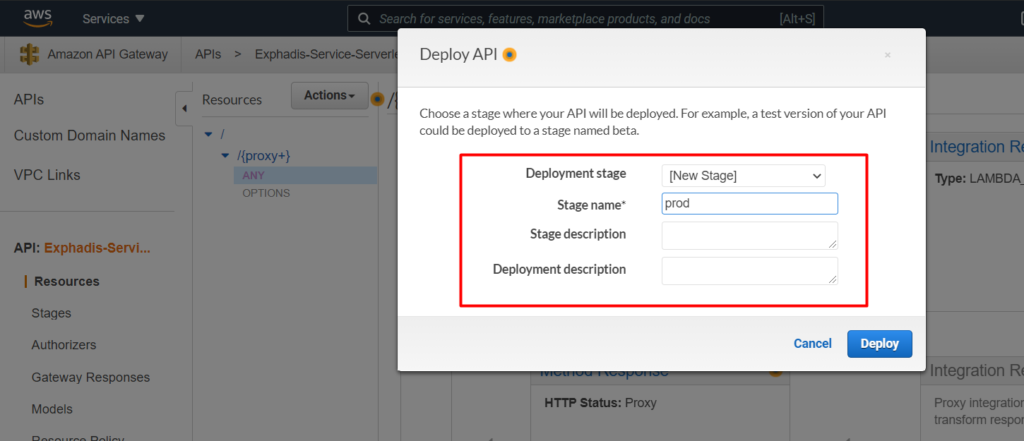
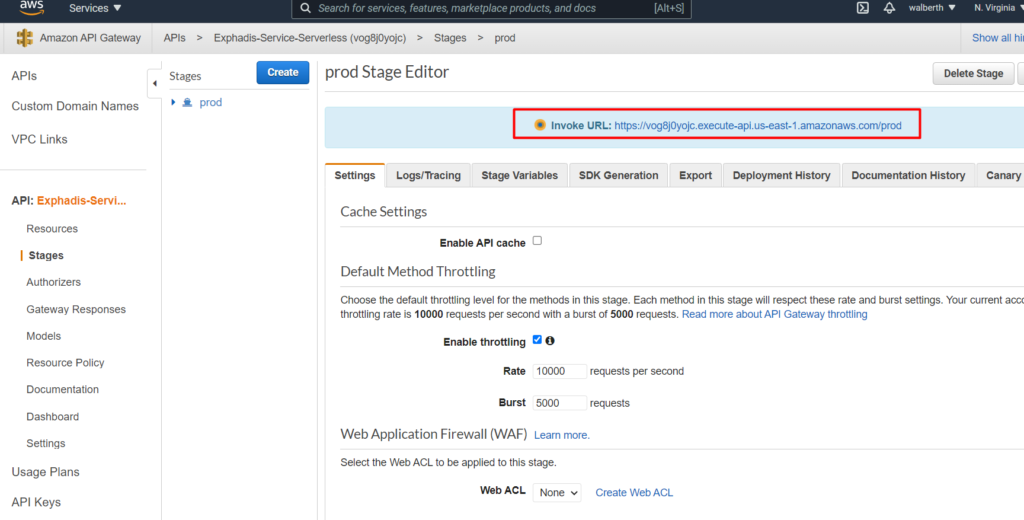
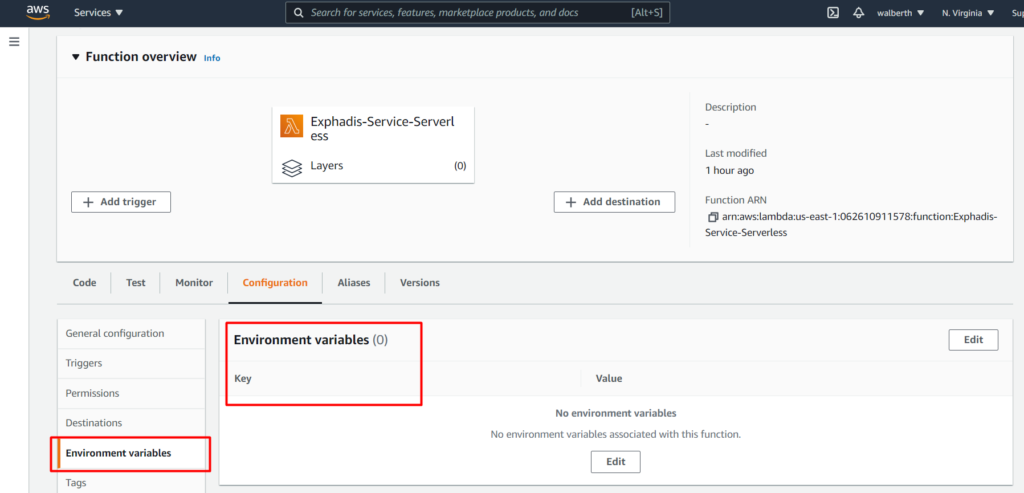
En este punto, para mi caso, es necesario configurar algunas variables de entorno, dado que sin esto va a fallar nuestra ejecución. Para poder hacer esto, debemos ir a nuestro lambda, a configuración y adicionar las variables de entorno.
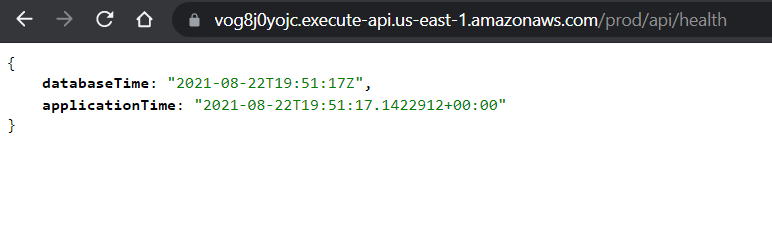
Finalmente, vamos a realizar la prueba de uno de los siguientes endpoint que tiene nuestro api. En mi caso es un get a un «health» que me permite obtener la fecha y hora del servidor y también de la base de datos, esto con la finalidad de determinar si todo esta funcionando correctamente. El endpoint a consumir sería el siguiente.
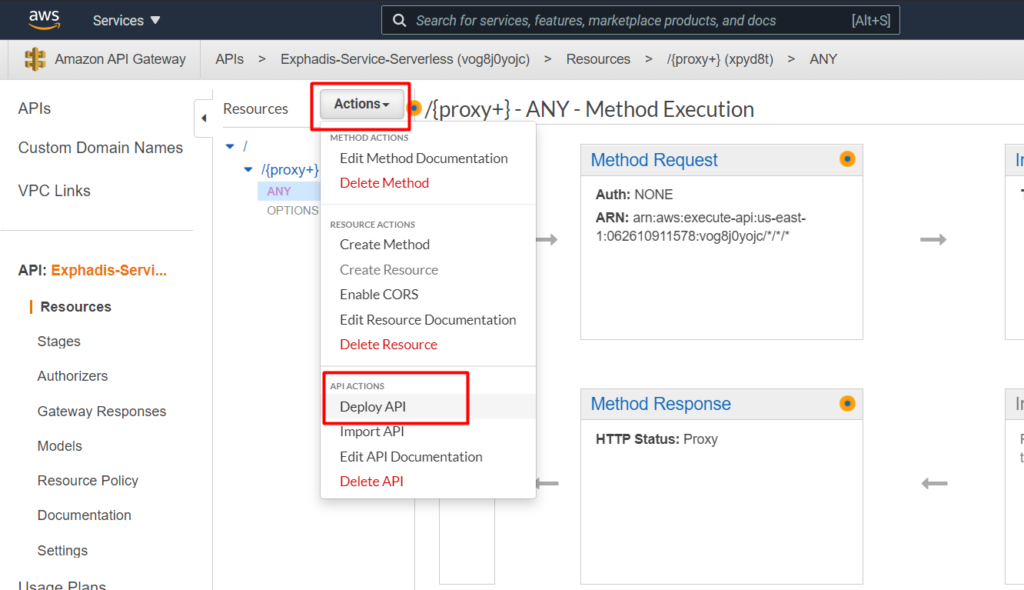
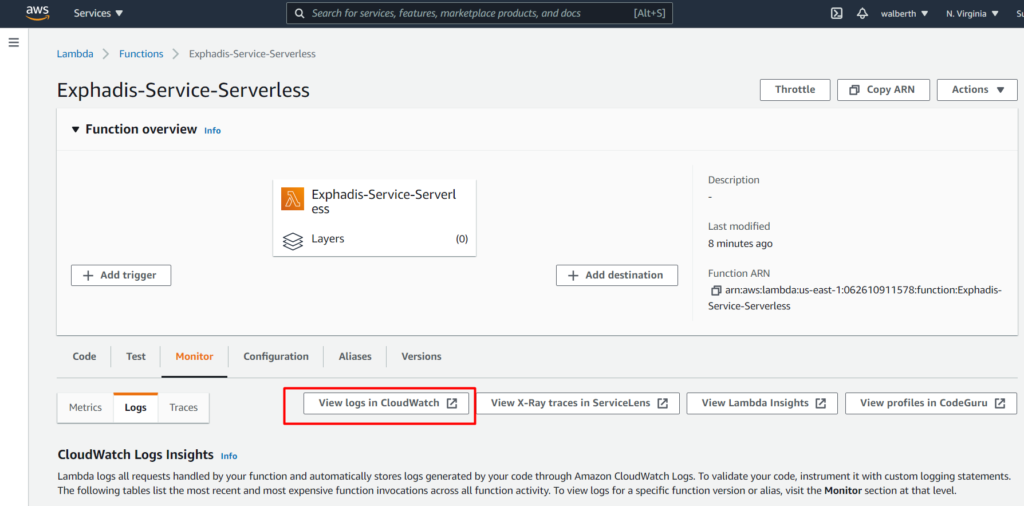
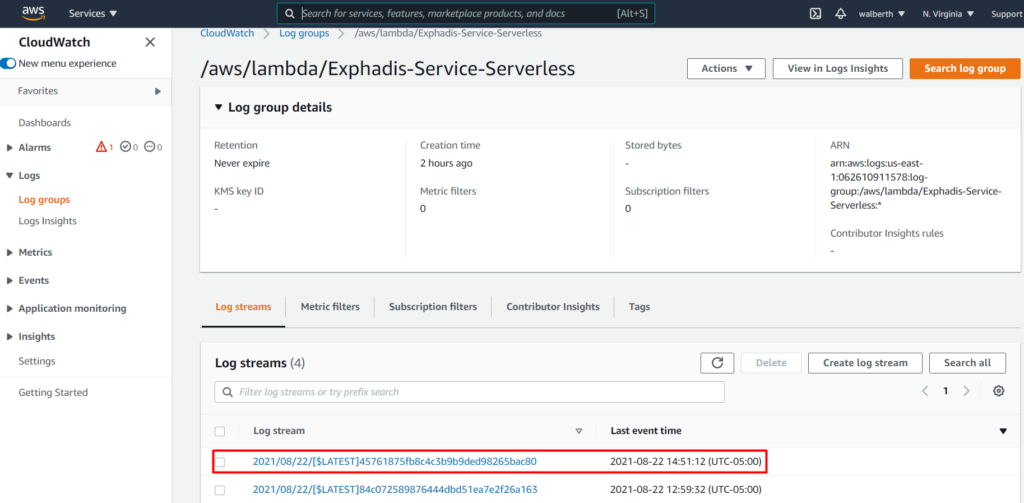
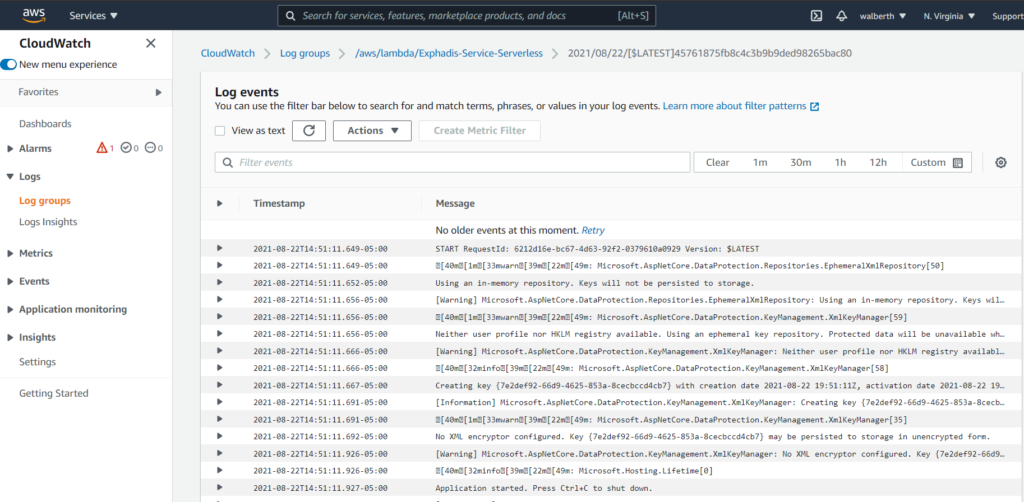
Si quisieramos ver el log de nuestro lambda, tenemos que ir a la opción «Monitor», y luego ir a cloudwatch a ver los LogGroups que se crean cada ves que consumimos nuestro api.
Finalmente, sólo voy a comentar que a este endpoint que hemos generado en AWS API Gateway, podemos mapearlo a otros domains, para esto tenemos una opción que se llama «Custom Domain Names», en esta tenemos que indicar cual es el domain que queremos, además nos permite mapearlo a algún certificado que hayamos solicitado previamente para que nuestra api se pueda servir sobre https.
Por otro lado, como explico un poco en el video adjunto en este post, nuestro lambda es manejado enteramente por AWS, sin embargo, nosotros podemos agregar «layers» para poder realizar ajustes sobre nuestro ambiente, en tre los cuales se pueden manejar la instalación de otras librerías en nuestro ambiente de trabajo.
Finalmente, en un siguiente post, voy a mostrar como podemos integrar este flujo en un pipeline de devops con azure devops.
Espero que esten bien, cuidense.
Saludos.
1 comentario