Si quieres entender Change Data Capture (CDC) sin quedarte en la teoría, esta demo tiene un objetivo muy concreto: mostrar cómo un cambio en una tabla de SQL Server termina convertido en un evento de Kafka usando Debezium y Kafka Connect, todo orquestado con Docker Compose.
Para que el recorrido sea claro y útil, dividí el contenido en dos partes. En esta primera parte me concentro en la arquitectura, el flujo de datos y las decisiones de diseño. En la segunda parte dejo la guía operativa para levantar la demo, validarla y probar INSERT, UPDATE y DELETE de punta a punta.
Parte 2: Cómo levantar la demo paso a paso.
Qué problema resuelve CDC
En muchos sistemas, la base de datos es la fuente de verdad y al mismo tiempo el punto donde nacen eventos valiosos para otros consumidores: analítica, sincronización con otros sistemas, motores de recomendación, pipelines de auditoría o paneles en tiempo real. El problema es que convertir cada cambio en un evento sin acoplar la aplicación no siempre es trivial.
Ahí entra CDC. En lugar de modificar la aplicación para publicar mensajes manualmente, el patrón captura los cambios desde la base de datos y los expone como un stream de eventos. En esta demo, esos eventos se publican en Kafka y luego pueden ser consumidos por distintos clientes, incluido un visor web en vivo.
Arquitectura general de la demo
La solución está compuesta por cinco servicios dentro de la red Docker cdc-net: SQL Server como origen, Kafka en modo KRaft como broker, Kafka Connect con Debezium como capa CDC, Kafka UI para inspección y un web viewer propio para visualizar eventos en tiempo real.
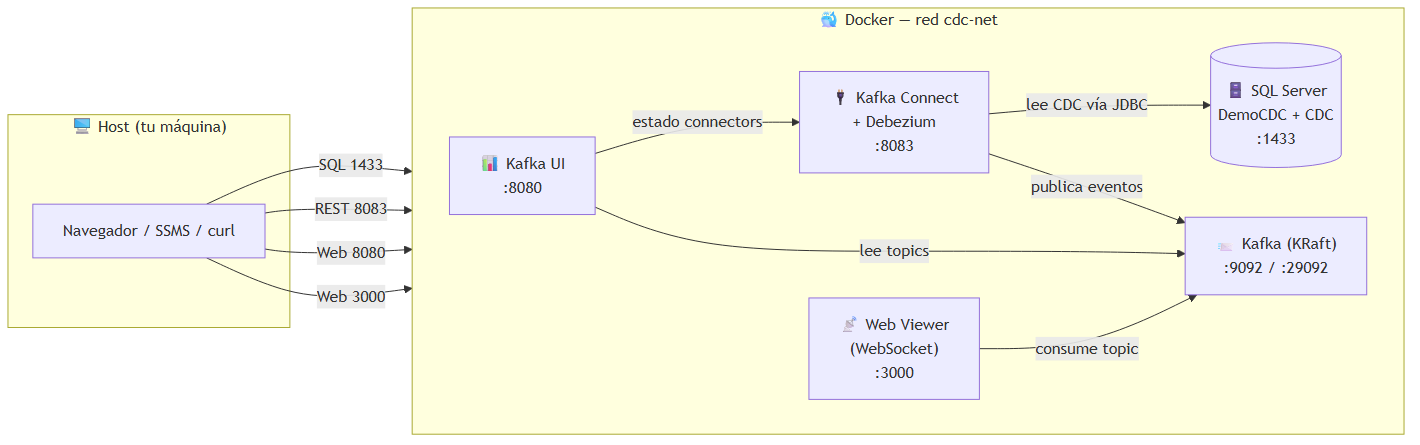
Qué hace cada componente
- SQL Server 2022: contiene la base de datos DemoCDC y la tabla dbo.Clientes, con CDC habilitado a nivel de base y de tabla.
- Kafka en modo KRaft: actúa como broker de eventos sin necesidad de Zookeeper, lo que simplifica mucho la demo.
- Kafka Connect + Debezium: registra un SqlServerConnector que hace primero el snapshot inicial y luego entra en modo streaming.
- Kafka UI: permite inspeccionar topics, mensajes y estado de connectors desde el navegador.
- Web Viewer: es un consumidor más del topic, implementado con Node.js, KafkaJS y WebSocket para mostrar los eventos en vivo.
Un detalle importante es que el web viewer no forma parte del pipeline CDC en sí. Está desacoplado del proceso de captura y publicación; se comporta como lo haría cualquier otro consumidor real de Kafka.
Cómo fluye un cambio desde SQL Server hasta Kafka
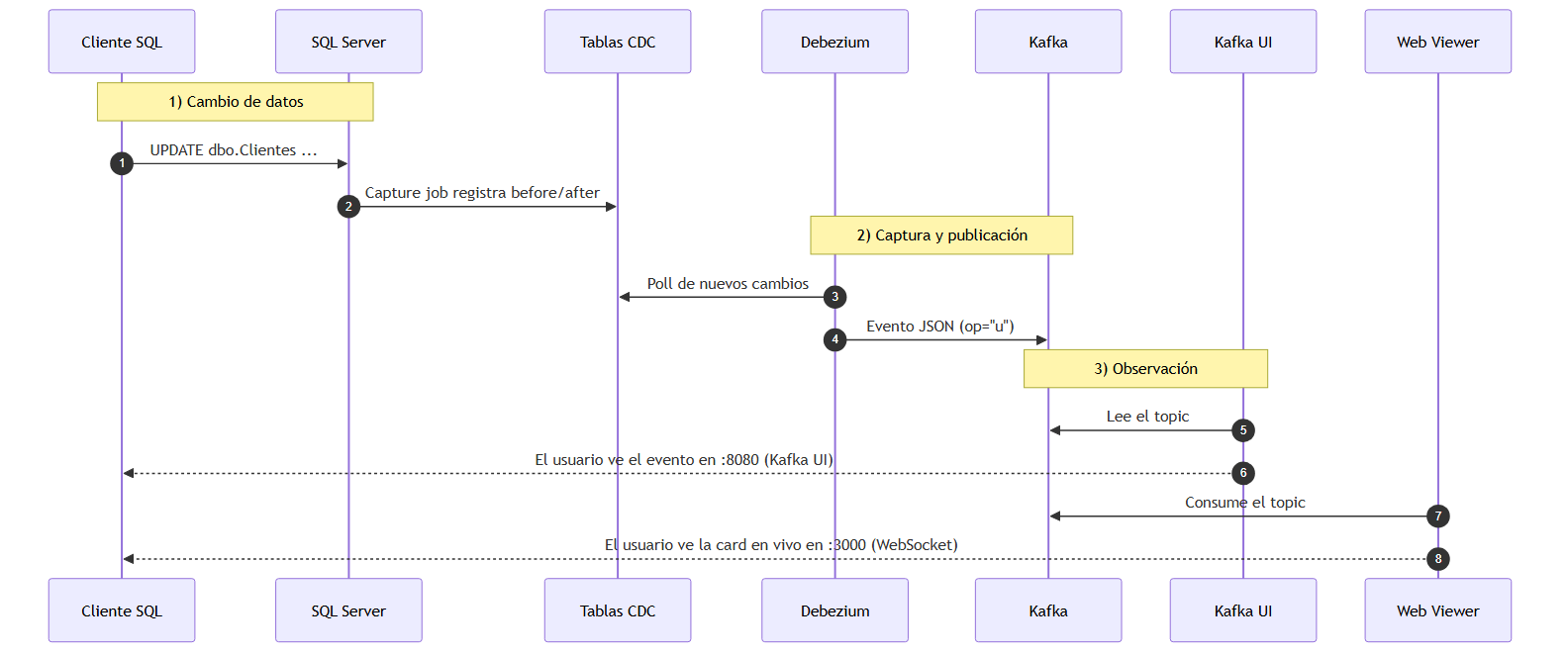
El flujo de datos empieza con un INSERT, UPDATE o DELETE sobre dbo.Clientes. SQL Server registra ese cambio en su transaction log y, a través de los capture jobs del SQL Server Agent, lo refleja en las tablas de CDC. Debezium no hace polling con SELECT sobre la tabla de negocio: lee ese mecanismo nativo y genera un evento estructurado con metadatos de origen, operación y estado antes/después.
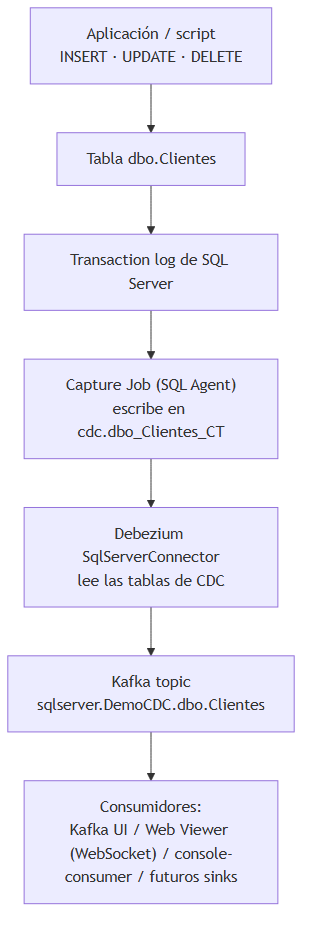
Ese evento se publica en el topic sqlserver.DemoCDC.dbo.Clientes. A partir de ahí, cualquier consumidor puede reaccionar: Kafka UI para inspección manual, el visor web para una demo visual o futuros sinks hacia otros sistemas.
Por qué usé Debezium y Kafka Connect
Para este caso, Debezium resuelve mejor el problema que alternativas como polling con JDBC, triggers o tablas de auditoría manuales. La ventaja principal es que aprovecha el CDC nativo de SQL Server y produce eventos ricos con before, after, op y source.
| Opción | Ventaja | Desventaja |
|---|---|---|
| Debezium | Captura INSERT, UPDATE y DELETE de forma no intrusiva y con eventos completos | Requiere comprender Kafka Connect y la configuración del connector |
| Polling con JDBC Source | Arranque simple | No detecta bien DELETE y puede perder cambios intermedios |
| Triggers + auditoría | Control total | Acopla la lógica CDC a la base y complica mantenimiento |
Además, Kafka Connect aporta una capa muy valiosa para demos y para producción: el connector se registra por JSON, queda observable por REST y se puede reiniciar, borrar o inspeccionar sin tocar código de negocio.
Por qué Kafka en modo KRaft y por qué Docker Compose
Elegí KRaft porque reduce complejidad. En una demo local, tener un contenedor menos importa: menos servicios, menos coordinación y menos puntos de fallo en el arranque. Kafka ya no necesita Zookeeper para este escenario y eso hace el stack más didáctico.
Docker Compose también fue una decisión deliberada. Permite levantar todos los componentes con un único archivo declarativo, encapsula dependencias y vuelve reproducible la demo en cualquier equipo con Docker. Para explicar CDC de forma clara, eso vale más que montar Kubernetes o un entorno más complejo desde el inicio.
Ventajas y límites de esta demo
La principal ventaja es que el flujo completo queda a la vista: base de datos, mecanismo CDC, connector, broker y consumidores. Eso hace que sea una base excelente para aprender y para enseñar el patrón.
- Ventajas: reproducibilidad, observabilidad, separación clara de responsabilidades y un consumidor visual pensado para demos.
- Límites: un solo broker, replicación 1, seguridad mínima, JSON con schema embebido y ausencia de un sink persistente real.
Es decir: el patrón es el correcto, pero el despliegue está optimizado para claridad y velocidad de arranque, no para tolerancia a fallos ni endurecimiento de seguridad.
Qué cambiaría en un entorno productivo
Si esta demo evolucionara a producción, el primer salto sería endurecer seguridad y disponibilidad: varios brokers Kafka, replicación mayor, TLS, autenticación, secretos gestionados y un usuario de base de datos con permisos mínimos en lugar de sa. El siguiente paso natural sería introducir Schema Registry, métricas con Prometheus + Grafana y, por supuesto, al menos un sink connector hacia un sistema analítico o de búsqueda.
También sería buena idea aplicar transformaciones SMT para aplanar eventos o enmascarar campos sensibles, según el uso posterior de los datos.
Conclusión
La idea central de esta arquitectura es simple: desacoplar el cambio en la base de datos de los sistemas que reaccionan a ese cambio. SQL Server sigue haciendo de origen transaccional; Debezium se encarga de traducir cambios a eventos; Kafka los distribuye; y consumidores como Kafka UI o el Web Viewer permiten observar el resultado casi en tiempo real.
En la segunda parte dejo la guía operativa completa: cómo levantar el stack, inicializar la base, registrar el connector, validar el snapshot y probar INSERT, UPDATE y DELETE paso a paso. Ademas de ver en un video todo esto funcionando y compartir la demo en un repo de github.
Deja un comentario