Esta semana me toco estar en una reunión donde entre otras cosas se discutía el desarrollo de un nuevo microservicio que permita suplir alguna necesidad del negocio, y mientras se exponían puntos de vista sobre que deberíamos considerar, se tuvo un debate ameno sobre el uso de un ORM para tener acceso a datos en una base de datos relacional. Esto me llevo a querer hacer una demo sobre como funciona entity framework con NetCore 3.0, como se debería configurar para conectar a una base de datos y poder obtener información.
Así nace este post, tenemos un proyecto básico que nos permite conectarnos a una base de datos en MySQL, y que con EF podemos tener acceso a su información. Aproveche para configurar algunas cosas adicionales en el proyecto que también voy a explicar.
Primero quisiera comentar que mi historia con EF, no siempre fue la mejor. Cuando inicie en mi primer trabajo como practicante recuerdo que el sistema que tenían usaba ADO.Net con la ejecución de procedimientos almacenados, y en ese tiempo el lider técnico era un evangelizador de los beneficios que brindaba poder modificar los procedimientos sin necesidad de tener que realizar un deploy de la aplicación. Y asi es como yo inicialmente no tuve mucho contacto con EF, en trabajos venideros empece a aprender más sobre bases de datos, sobre distintos tipos de ORM, y poco a poco me fui interesando sobre el potencial que tenía EF, hasta que llego un proyecto en el que pude verlo en extenso y ser testigo de todo el potencial que esconde, claro con los problemas que también puede acarrear.
Digo problemas, por que si es mal usado puede devenir en un ineficiente manejo de la base de datos, todo depende de como lo usen los desarrolladores y que prácticas se sigan. Ahora si, veamos el proyecto.
Partimos ejecutando el siguiente script de la base de datos, que pueden encontrar en la carpeta scripts del repositorio.
Veamos un poco el diagrama entidad relación de esta base de datos de demo.

Como podemos ver, tenemos un diagrama con 12 tablas, entre las cuales de modo básico tenemos el manejo de las direcciones de una persona, y los estudiantes. Veremos más a detalle como se vincula la información en el video. Revisemos, ahora el proyecto.
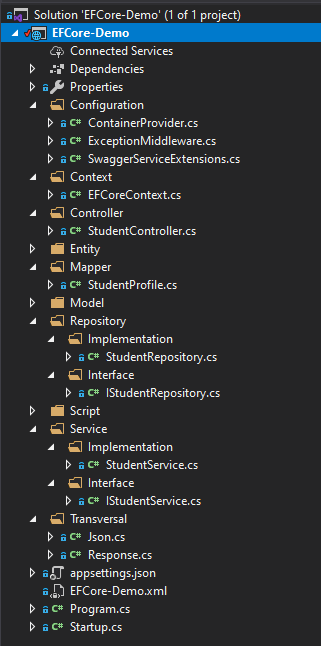
Repasemos cada una de las carpetas y como se han dividido.
- Configuration: Acá he puesto algunos archivos de para el correcto funcionamiento del proyecto, el archivo «ContainerProvider.cs» es para la inyección de dependencia, «ExceptionMiddleware.cs» nos permite capturar alguna excepción no controlada que se pueda generar en la ejecución de la aplicación y centralizar las acciones que tomen y finalmente «SwaggerServiceExtensions.cs» que nos permite realizar la configuración de swagger para generar documentación en nuestra API.
- Context: En esta carpeta, se tiene el archivo «EFCoreContext.cs» que nos permite configurar entity framework, las relaciones entre las distintas tablas entre otras cosas.
- Controller: Acá irán todos los controladores que necesitemos exponer en nuestra API.
- Entity: La entidad que obtendremos de la base de datos.
- Mapper: Estamos usando automapper en el proyecto, en esta carpeta pondremos los distintos profiles que requiramos crear para realizar el mapeo de nuestra información.
- Model: En esta carpeta pondremos todas los DTO, que se expondrán como información por nuestro API.
- Repository: Esta carpeta será nuestro repository, para el cual tenemos la interfaz, y su implementación.
- Script: Acá estoy dejando ciertos archivos importantes para poder levantar la demo, el script de base de datos, diagrama E-R, etc.
- Service: Acá pondremos la lógica de negocio que consideremos necesaria. También tiene la interfaz y su implementación.
- Transversal: Pondremos acá distintas utilidades que podemos usar en el proyecto.
Para no entrar en detalle de la configuración en EF de todas las entidades, tomemos como modelo a la entidad «person».

Como podemos ver, nos valemos de las «DataAnnotations» que nos permitan indicar el nombre de la tabla que se va a mapear a una entidad, del mismo modo con las columnas, en caso posean un nombre distinto en la base de datos. Mediante estas anotaciones es posible especificar más información, como las relaciones entre las tablas o las llaves primarias y foraneas que se tienen. Sin embargo, particularmente prefiero indicar estas relaciones en el context.
Veamos que configuración se tiene en este archivo.
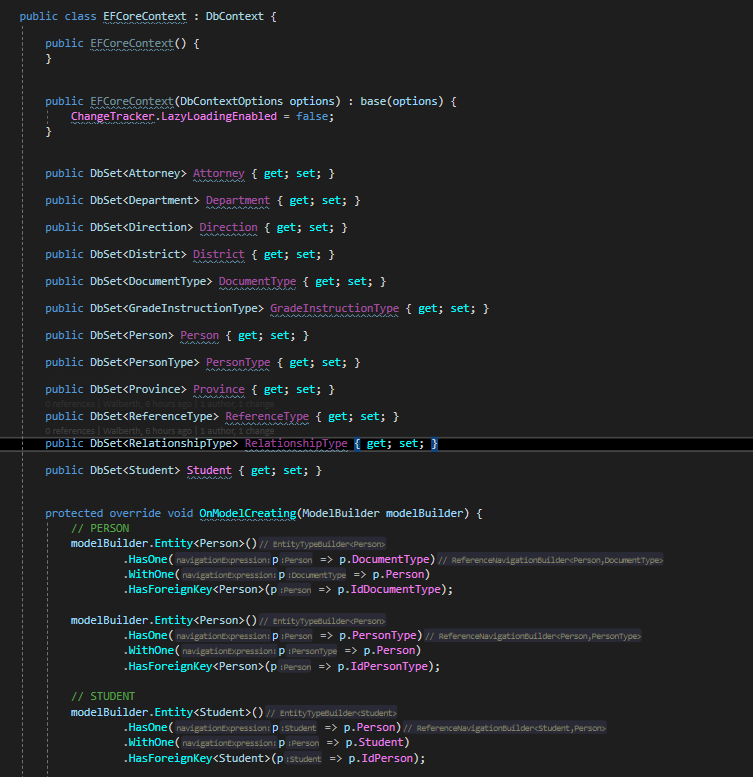
Como podemos ver, es necesario realizar un override al método «OnModelCreating» y ahí especificar las relaciones entre las distintas tablas, así como también las llaves foraneas. Entre otro tipo de configuración con la base de datos que sea necesario realizar. Revisemos ahora el repositorio y como estamos obteniendo la información.

Tenemos una interfaz que declara un método asyncrono que permite obtener el listado de estudiantes y en su implementación hacemos uso de EF para obtener esta información con los joins que son necesarios para nuestra demo. En la capa de servicio, tenemos los siguiente.
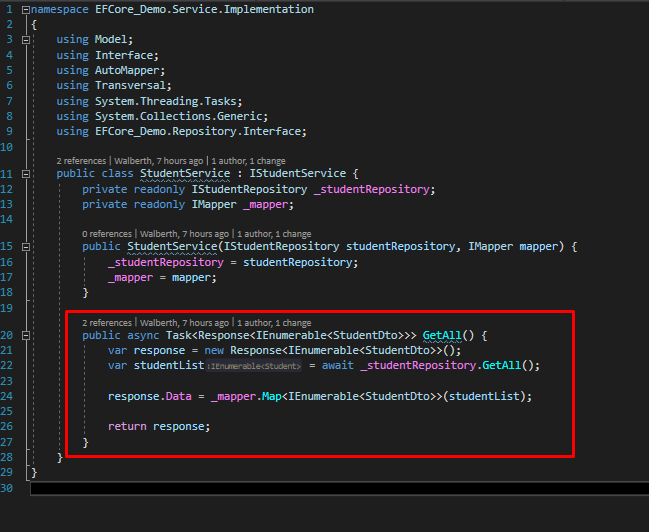
Tenemos la implementación de la interfaz para la capa de servicio, como se puede ver, se obtiene del repositorio la información y luego se realiza un mapping de estos campos para el DTO que terminaremos devolviendo en el API. Notemos que no tenemos ningún try-catch hasta ahora en nuestro código, esto dado que se a implementado un middleware que nos permita centralizar los errores. Veamos como se implemento esto.
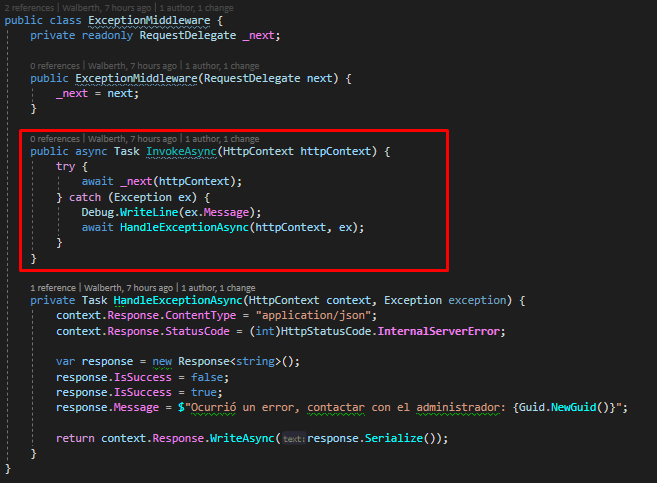
Si ocurriera algún error en la ejecución de nuestra solicitud, se terminará entrando en nuestro método «HandleExceptionAsync» acá podríamos tomar las acciones necesarias, para la demo estoy devolviendo un error genérico que un GUID autogenerado por cada error.
El proyecto no es nada del otro mundo, con respecto a lo que ya hayamos visto con net core, pero me parecío interesante hacer una guía sobre como usar EF. Pueden revisar el video en donde seguro hablo a más detalle sobre algunas cosas de la implementación del proyecto, el proyecto demo también esta en github por si quieres revisarlo y si hubiera alguna duda adicional pueden dejarme una pregunta.
REPO: GITHUB
Saludos.
3 comentarios







